OS가 파일을 어떻게 관리하는지 알아보자. 그렇기 위해선 파일시스템이 뭔지, 파일이 어디에 저장되는지 등을 알아야겠다.
먼저 파일이 저장되는 보조기억장치인 Disk에 대해서 알아보자.(HDD -기준)
Disk System
데이터를 영구적으로 저장하는 저장 장치이다.
비 휘발성이라는 특징을 가졌다.(영구적이므로.)
파일은 이 디스크에(보조기억장치)에 저장된다.
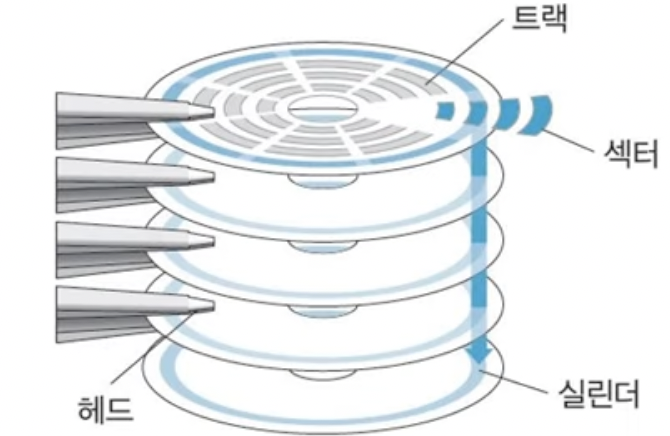
디스크는 이렇게 Disk Pack이라는 장치로 이루어져있다.
위에서 Disk Pack을 보면
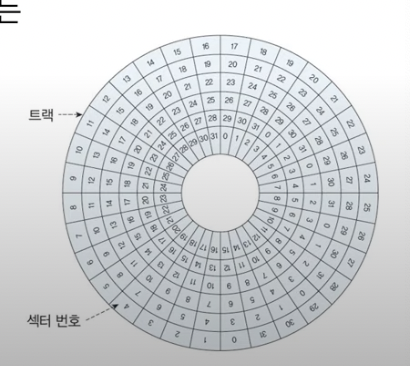
이렇게 생겼고, 각 섹터(섹터가 뭔지는 바로 아래서 알아볼것!) 마다 번호가 있는 것을 알수 있다. 스포하자면 이 섹터에 데이터가 저장된다.
Disk Pack
실제로 데이터가 디스크에 저장되는 하드웨어이다.
어떻게 구성되어 있는지 알아보자.
먼저 원들이 여러개 위아래로 있고, 원을 어떠한 집게같은 것이 지탱하고있다.
Sector
원을 보면 조그맣게 섹터라는 부분이 존재한다. 이 조그마한 부분에 데이터(0또는 1)이 저장된다.
Track
섹터들의 집합으로, 원의 중심으로부터 반지름의 길이가 같은 섹터들의 집합이다. 내부가 빈 원이라 생각하면 된다.
Cylinder
원이 위아래로 여러개있다. 트랙은 한 원에 대한 것이고, Cylinder는 같은 반지름을 가지는 트랙들의 집합이다.
Platter
계속 해서 원이라했는데 이 원을 Platter라 한다.
양면에 0, 1 이진 데이터를 저장할수 있어야 하므로 자성 물질을 입힌 원형 금속판이다.
데이터의 기록/판독이 가능한 기록매체이다.
Surface
Platter는 양면에 데이터를 기록하거나 읽을수 있다.
각 면, 윗면과 아랫면을 Surface라한다.
---> 데이터를 실제로 저장하고 읽는 Disk Pack의 구성요소를 하나씩 알아보았다.
그럼 이제 데이터가 저장되는 곳인 Disk Pack하드웨어에 대해서 알아보았는데 어떻게 읽고 기록하는지에 대해서도 알아보자!
Disk drive
Disk pack에 데이터를 저장하거나 읽을수 있는 하드웨어이다.
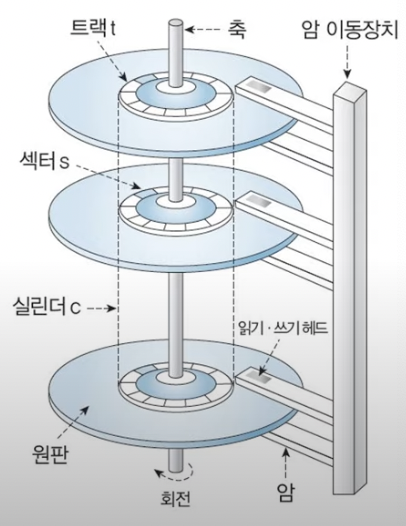
Disk Pack은 위 그림과 같이 중앙에 축같은 것이있고, 옆에는 직육면체로 길게 기둥같읕게있고, 기둥에서 여러개 직윤면체들이 Platter의 Surface를 바라보고 있다.
Head
Surface에 데이터를 기록/판독하는 장치이다. 보면 Surface를 바라보는 직윤면체중 조그맣게 회색으로된 부분이 있는데 그게 헤드(Head)이다. 이 조그마한 직사각형 회색부분에서 섹터에 데이터를 기록하거나 읽는다.
Arm
Arm은 헤드를 고정/지탱하는 장치이다. 보면 헤드를 고정하고, 엄청 긴 직윤면체에서 나온다.
그리고 Platter의 윗면 아랫면인 Surface를 둘다 헤드가 바라보고 있으므로 한 Platter마다 두개의 Arm이 있다.
Positioner
여러개의 Arm을 지탱하는 긴 직육면체이다.
이 장치가 Head를 원하는 트랙으로 이동시킨다.
그래서 헤드가 원하는 트랙에 데이터를 쓰거나, 해당 트랙으로부터 데이터를 읽는게 가능하다.
Spindle
Platter의 중심의 축이다. 고정되어있으며 회전축이다.
Disk Pack자체를 고정하기도 한다.
Spindle은 분당 회전수인 RPM이라는 단위를 가지고 있는데, 원하는 섹터에 헤드가 접근하기 위해선 Spindle이 회전해야 하며, 해당 RPM이 빠를 수록 섹터에 빨리 접근하기에 데이터 읽기나 쓰기가 빠르다!
그래서 하드디스크 보면 저장 용량과 , RPM이라는 정보가 있는것이다. 저장용량이 크면 섹터가 많다는 것이고, RPM이 높으면 Spindle의 분당 회전수가 빨라서 헤드가 원하는 섹터에 빨리 접근한다는 의미!
Disk Address
Physical disk address
헤드가 원하는 섹터에 접근하려면 디스크의 물리적인 주소가 있어야한다.(어딘지 알아야 접근이 가능하닌까!)

위와 같이 섹터를 식별하는 실제 디스크의 주소는 어떤 실런더인지, 또 윗면인지 아랫면인지 그리고 트랙중 어떤 섹터인지를 알아하므로 위의 정보들을 알아야 한다.
Logical disk address : relative address
그러나 하드디스크의 종류는 너무나 많고, OS가 디스크의 물리적인 주소를 모두 알아야 하는데는 한계가 있다.
그래서 OS는 디스크를 논리적인 주소인 Block(블럭)으로 본다.
즉, OS는 디스크를 블럭들의 집합으로 보는 것이다.
이 블럭을 Logical disk address라고 한다.
그럼 가상메모리때 했던 address mapping처럼, OS가 알고있는 logical address인 블럭을 physical address로 변환 해야겠네?
그렇다!!
---> 여기서 드라이버라는 개념이 나온다.
새로운 하드웨어 장치를 내 컴퓨터에 연결하면 드라이버부터 설치한 기억이 있는가? 나는 로지텍 마우스를 구입하고 컴퓨터에 연결하면 로지텍 마우스 드라이버를 설치한 경험이 있다. 이러한 드라이버는 해당 하드웨어의 제조사에서 만든 것이고, OS가 바라보는 블럭이라는 논리적인 주소를 실제 하드디스크의 주소로 매핑(변환)해준다.
Disk Address Mapping
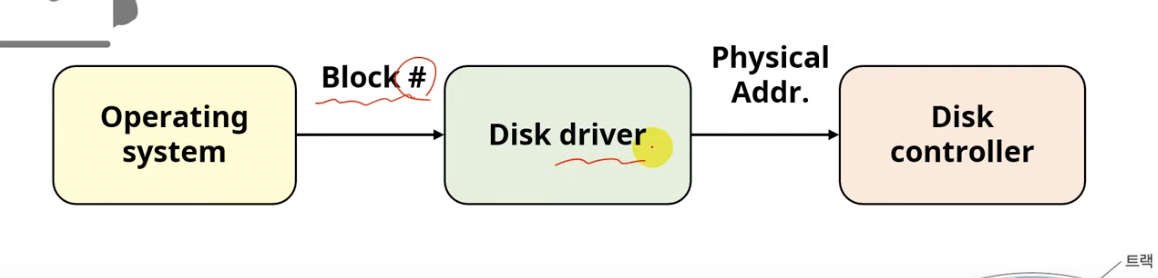
OS가 바라보는 논리적인 디스크의 주소인 블럭을 Disk driver를 통해서 실제 physical address로 변환해준다.
이 변환된 physical address를 통해서 실제 데이터가 저장된 섹터에 접근하여, 데이터를 읽거나 기록하는 것이 가능하다!
Data Access in Disk System
OS가 바라보는 디스크의 논리적인 주소인 Block을 실제 디스크의 섹터의 물리적인 주소로 드라이버를 통해 변환하였다. 이젠 해당 섹터에 접근하여 데이터를 읽거나 저장할수 있다.
근데, 헤드가 섹터에 접근한다했는데 실제로 헤드가 어떤 과정을 거쳐서 섹터에 접근하는 지 알아보자.(물리적인 관점에서)
Seek time
디스크의 헤드가 physical address에 맞는 sylinder로 이동하는 시간이다.
Rotational delay
Seek time이후, 필요한 Spindle이 회전하여 해당 섹터가 헤드위로 도착하는데 걸리는 시간이다.
(Spindle 의 RPM이 높으면 Rotational delay가 짧겠다.)
Data transmission time
섹터가 헤드아래로 이동한 후, 해당 섹터의 데이터를 읽어서 전송하거나, 데이터에 기록하는 시간을 의미한다.
즉, 실제로 데이터에 접근하여 작업을 수행하는 시간이다.
여기까지 실제로 파일이 저장되는 디스크 하드웨어에 대해서 알아보았다. 디스크는 보조기억장치로, Disk Pack의 섹터에 데이터가 저장되고 Disk drive의 헤드가 섹터를 가리켜 섹터에 저장된 데이터를 읽거나 섹터에 데이터를 저장한다. 그리고 OS가 디스크의 실제 섹터에 블럭을 통해서 접근하고, 해당 논리적인 주소는 드라이버를 통해서 물리적인 섹터의 주소에 접근하는 것도 알게 되었다. 접근하고 싶은 섹터의 물리적인 주소를 알게된 후, 헤드가 섹터에 접근해 데이터를 읽거나 저장하는 과정에 대해서도 알게되었다.
File system
이제 본격적으로 OS 파일 시스템에서 대해서 알아보자.
파일 시스템이란 사용자가 사용하는 파일들을 관리하는 OS의 한 부분이다.
File system은 어떻게 구성되어있을까?
- Files (연관된 정보들의 집합)
- Directory structure (시스템 내 파일들의 정보를 구성 및 제공)
- Partitions (파일들이 저장되는 디스크를 논리적으로 분할한 것)
로 구성되어있다.
File 개념
File이란 보조기억장치에 저장된 연관된 정보들의 집합이다.
- 보조기억 장치 할당의 최소단위이다.
- Sequence of byte(물리적 단위)
File 내용에 따른 분류
- Program file(source program, object program, executable files ..)
- Data file(데이터가 저장된 파일)
File 형태에 따른 분류
- Text(ascii) file (사람이 읽을수 있는 형태 - 사람이 볼수 있게 한번더 변환을 해야함)
- Binary file (사람이 읽을수 없는 이진 형태의 파일 - 따로 변환이 필요없음)
File 연산들(operations)
- Create, Write, Read, Reposition, Delete, ...
이러한 연산들은 OS가 제공한다.
어떻게? 사용자가 사용할수 있는 OS 기능의 집합인 System call을 통해서
File Access Methods(파일 접근 방법)
- 순차 접근(Sequential access)
File을 처음 부터 byte단위로 순서대로 접근하는 방법. (fgetc) - 직접 접근(Directed access)
원하는 블럭을 직접 접근 (lseek, seek) - 인덱스 접근(Indexed access)
Index를 참고하여 원하는 블럭에 접근
그외 파일 시스템을 구성하는 녀석들
- Partitions(minidisks, volumes)
보조기억장치인 디스크를 논리적으로 분할한 단위이다.
가상 디스크라고도 한다.(virtual disk)
디스크 하나를 여러개의 파티션으로 나눌수도 있고, 디스크 두개를 하나의 파티션으로 합칠수도 있다.
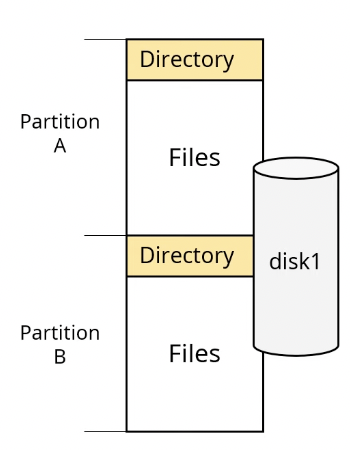
(하나의 디스크를 두개의 파티션으로 분할한 경우 - 물리적인 disk하나를 논리적인 단위인 파티션으로 두개로 분할함)
- Directory
파일들을 분류, 보관하기 위한 개념이다.
directory에도 연산을 할수 있다.(파일 찾기, 파일 생성, 파일 삭제, 디렉토리 list보기 ..)
이러한 연산(operations)들도 OS가 제공하는 기능이다, system call을 통해서 OS가 제공하는 기능을 이용할수 있다.
Mounting
현재 File system에 다른 File system을 붙이는 것을 의미한다.

Directory Structure
파일을 분류하는 구조인 디렉토리에 대해서 알아보자.
디렉토리에서 파일을 생성, 삭제, 디렉토리를 생성 삭제 모두 OS가 제공한다. (system call을 통해서 사용자는 OS기능 이용 가능)
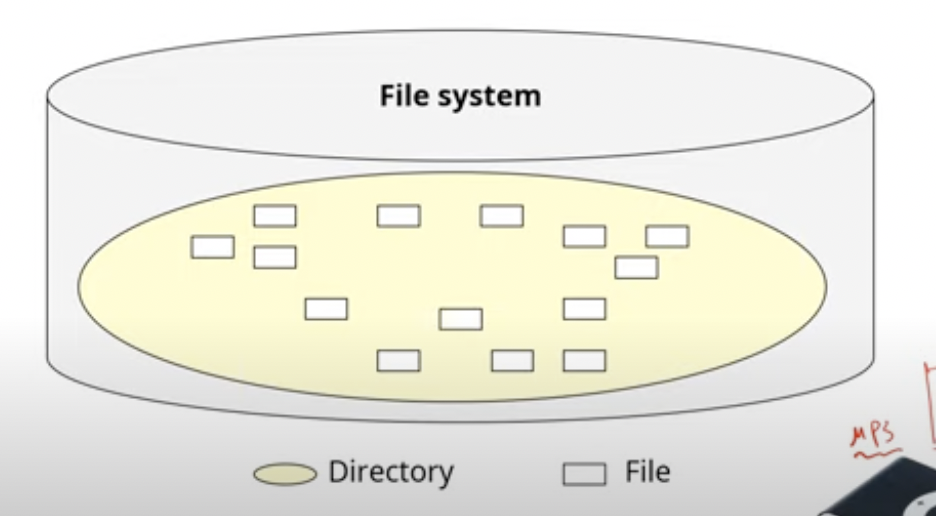
Flat Directory Structure
말 그대로 평평한 디렉토리 구조이다.
File System내에 디렉토리가 단 하나만 존재하는 구조이다.
디렉토리가 하나밖에 존재하지 못하니 파일의 이름을 짓기도 어렵고, 다중 사용자 환경에서는 문제가 상당히 많겠다.(다른 사용자가 이미 있는 파일을 생성하면 덮어 씌워질수 있음..) 그리고 디렉토리가 하나밖에없으니 파일 관리하기도 매우 어렵겠다.
(옛날에는 파일시스템이 이 디렉토리 구조였다. mp3를 생각하면 디렉토리는 루트하나만 있고, 파일을 해당 디렉토리에만 넣는 기억이 있을 것이다.)
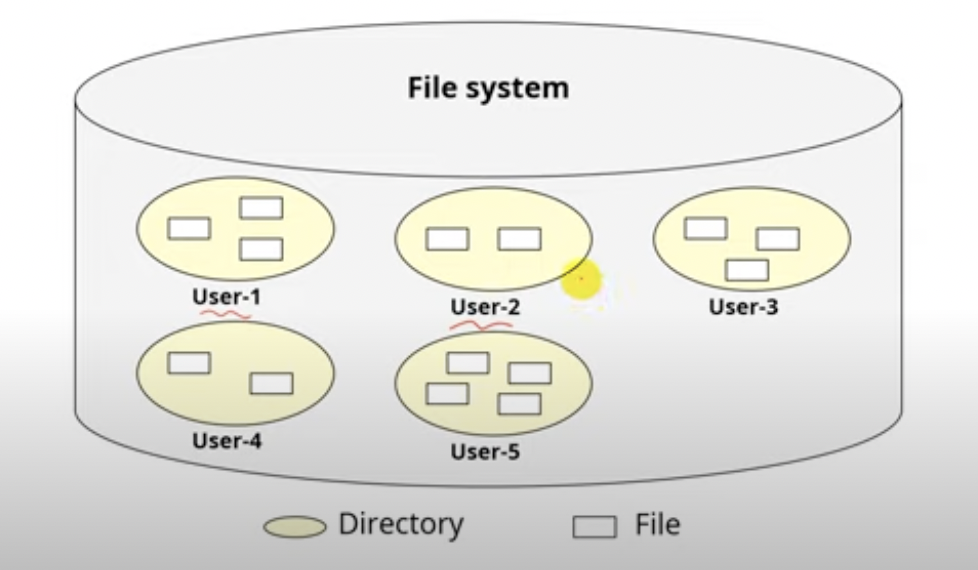
2-Level Directory Structure
디렉토리가 두개이다.
즉, 사용자마다 개개인의 디렉토리를 가져 파일들을 관리할수 있다.(다중 사용자 환경 시스템에서 사용될순 있겠다.)
그치만 사용자는 자신의 디렉토리에서 sub directory를 생성할수 없기에 한계가 있다..
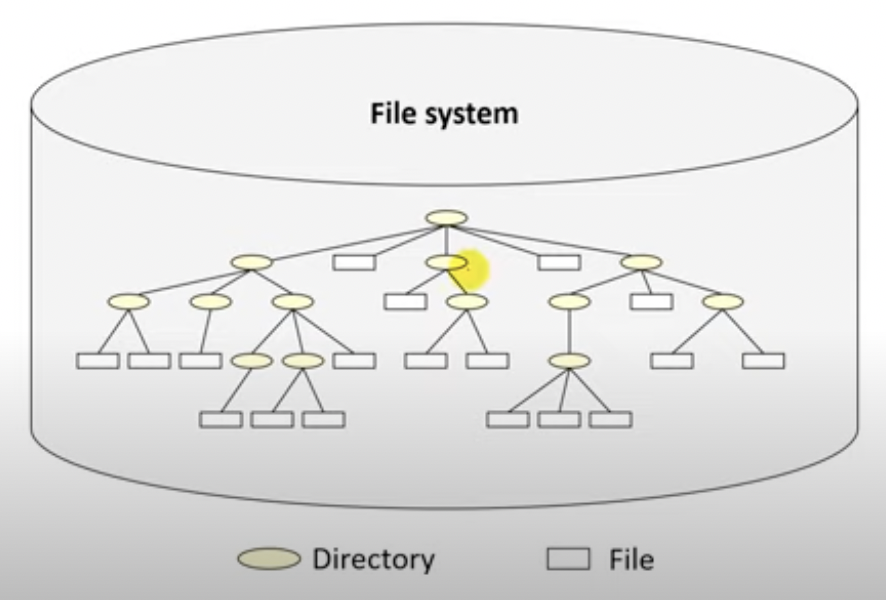
Hierarchical Directory Structure
우리가 많이 사용하는 계측적 디렉토리 구조이다. 트리형태로 디렉토리가 존재하고 sub directory를 만들수 있다.
(대부분의 OS가 사용한다.)
이 디렉토리 구조에서 Home Directory, Current Directory, Absolute Path, Relative Path등의 개념이 나왔다.
Acyclic Graph Directory Structure
아래로만 쭉쭉 뻗어나가던 트리형태의 디렉토리 구조만 보았는데 이 구조는 그래프 형태로 하위 노드 이외에도 노드간 연결이 될수 있다.
이름처럼 Acyclic 으로 cycle형태가 되지 않는 그래프 디렉토리 구조이다.
이 디렉토리 구조에서 Link라는 개념이 사용된다.
Link란 A라는 디렉토리와 B라는 디렉토리간 상 하위 관계가 아님에도, 관계가 있어 바로 접근할수 있는 걸 말한다. 윈도우에선 바로가기!
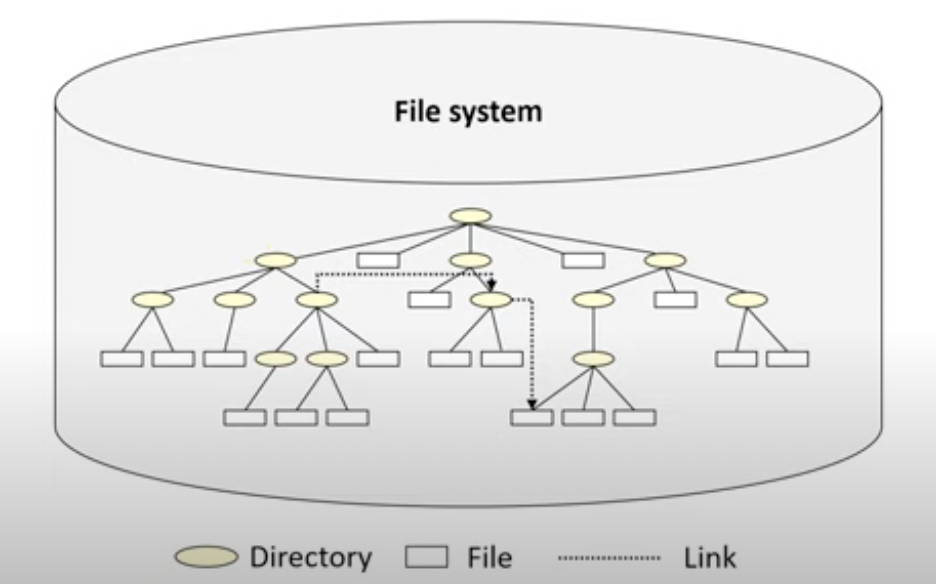
General Graph Directory Structure
Acyclic Graph Directory Structure의 일반화로 Cycle(노드간 순환)을 허용한다.
파일 탐색시 무한 루프에 빠질수있다.
~/Desktop/link
디렉토리에는 dir 디렉토리가 있는 상황이다.
ln -s dir alink
로 dir를 향하는 alink 링크파일을 만들면

요런식으로 된다.
cd alink
를 한뒤
echo "hello" > hello.txt
를 하면
dir디렉토리에 hello라고 적힌 hello.txt 파일을 볼수있다.
여기서 순환을 허용하는 그래프 디렉토리 구조는 dir 디렉토리에서 ~/Desktop/link 에 링크를 건 링크 파일을 만들면 순환이다.

무한 파일탐색을 볼수있다.!!
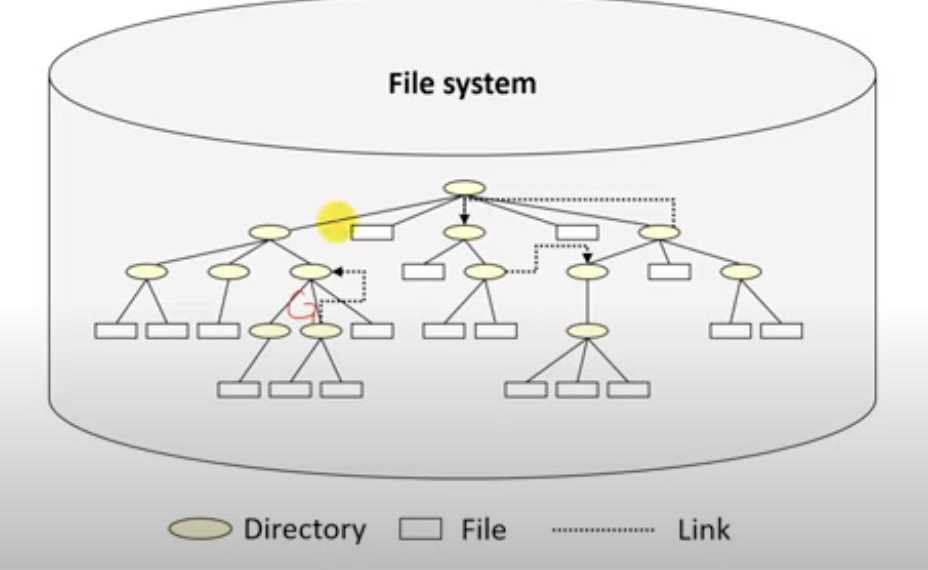
파일 시스템에서 사용되는 디렉토리 구조들을 알아보았다. 매우 간단했다.!
File Protection
시스템에는 매우 많은 파일이 존재할 것이다.
각 파일들에대한 접근권한이라는 개념이 없다면 누구든 파일에 접근해서 R, W, X, A를 할수 있을 것이다.
다중 사용자 시스템에서 다른 사용자가 내 시스템의 파일에 함부로 접근하면 큰 문제가 발생할수있다!! (같은 아파트 사는 다른 주민이 내 집에 함부로 들어오는 것과 동일!!)
그래서 파일마다 접근권한을 주는 파일 보호를 OS는 어떻게 하는지 알아보자.
OS가 제공하는 기능인 여러 연산(Read, Write, Execute, Append..)에 대해선 접근 제어가 필요하다.
File Protection Mechanism
파일 보호 매카니즘에는 크게 두가지가 존재한다.
- Password기법
파일마다 비밀번호를 설정해두는 것이다. 그런데 한 시스템에 파일은 매우매우매우매우 많다. 각 파일에 모두 비밀번호를 설정하면 기억하기가 불가능! Not Practical!! - Access Matrix 기법
사용자가 파일에 접근할수 있는 권한이 저장된 표를 이용하는 것이다.

(Domain이란 파일에 접근하는 주체인 사용자, 프로세스 이고 Object란 접근당하는 개체 즉 파일을 의미한다.)
위 표가 Access Matrix이다.
보면 D1이라는 도메인(사용자)는 F1, F2, F4 오브젝트(파일)에 Read할수있고 F4 오브젝트에는 Write까지 할수 있는 정보가 적혀있
파일 보호는 도메인과 파일에대한 접근권한이 적힌 표로 쉽게 실현할수있다.
그러나 단점이있다.
빈공간이 많다..
이게 무슨 문제냐면 Access Matrix자체의 사이즈가 불필요한 빈공간때문에 너무커서, 관리하는데 오버헤드가 있다.
그래서 Access Matrix의 단점을 해결하기 위한 여러 기법이 존재한다.
Access List
Access Matrix의 칼럼이다.
즉 한 오브젝트(파일)에 접근하는 모든 도메인과 도메인의 권한이 적힌 칼럼이다.
List이기 떄문에 해당 오브젝트에대한 권한이 필요없는 도메인에 대한 데이터는 아애 없으면되기에 Access Matrix의 빈공간 낭비라는 단점을 해결!
실제 OS에서 많이 사용된다.
Unix에서도 ls - l명령어를 치면 파일에 대한 권한이 적혀있다.(rwxr--r--) 앞의 세개는 Owner, 그다음 세개는 그룹의 권한, 마지막 세개는 그외 도메인에 대한 권한이다. 이렇게 실제로 많이 사용되는 기법이다.
Access List의 단점
- 도메인(사용자)가 오브젝트(파일)에 접근할 때마다 Access List를 뒤적 뒤적해서 자신의 권한을 확인해야한다. 해당 오브젝트에 자주 접근하는 도메인이라면 계속 Access List를 뒤적뒤적해야하는 오버헤드가 있다. 성능면에서 단점이다.
Capability List
Access Matrix의 로우이다.
즉, 도메인(사용자)이 모든 파일에 대해 접근하는 권한이 적혀있는 List이다.
사용자가 가지고 있는 권한 목록이므로 중요하기에 시스템이 자체적으로 저장하고 있어야한다.(커널안에 저장하고 있다.)
도메인이 접근하려는 오브젝트에게 자신의 권한을 제시하고 시스템이 검증하는 과정으로 동작한다.
Capability List의 단점
- 커널안에 계속 저장하고있어야 하기에 그만큼의 오버헤드가 있다.
- 한 오브젝트에 접근하는 모든 R권한을 없애고 싶으면 Capability List를 모두 돌면서 삭제해야하는 단점이있다.
(위 상황에서 Access List는 한 오브젝트 List만 보면되지만 Capability List는 모든 List들을 다 뒤적뒤적해야하기에 단점이다.)
Lock-key Mechanism
Access List + Capability List
사용자는 키를 가지고있고 오브젝트는 자물쇠로 잠겨져있다.
사용자가 키를 이용해서 오브젝트에 접근하는 과정으로 동작한다.
key list정보는 시스템에서 관리해야한다.(중요하므로)
Access List와 Capability List는 각각 장단점이있따. 이렇게 장단점이있으면 하이브리드해서 사용하곤 한다.
많은 OS가 실제로 사용하는 File Protection
도메인이 처음 오브젝트에 접근하면 Access List를 확인하고 이때, Capability를 생성후 도메인에게 전달한다. 도메인은 이 Capbility로 계속해서 해당 오브젝트에 접근할 때마다 쉽게 접근할수 있다. 그리고 마지막 접근시에는 Capability를 삭제한다.
즉, 어떠한 파티에 입장할때 처음에 초대 목록을 보고 초대목록에 있는 사람이면 파티에 입장하게 하고 그 동시에 출입증을 준다. 그리고 해당 사람은 파티 도중 잠깐 편의점을 가더라도 다시 파티장에 입장할때 출입증으로 쉽게 접근할수 있따. 그리고 파티가 끝나고 집에가려는 사람은 해당 출입증을 반납한다.
이렇게 실제 상황과 매우 유사하다!!
Allocation methods
파일들을 디스크에 어떤식으로 저장하는지, 할당하는 방법들이다.
파일은 보조기억장치(디스크)에 저장된 연관된 정보들의 집합이다.
Continuous Allocation
파일들을 디스크의 연속된 블럭에 할당하여 저장하는 방법이다.

위 그림처럼 파일을 연속된 블럭(번호가 1, 2, 3, 4인 블럭)에 저장하는 기법이다.
파일에 순차적으로 접근과, 직접접근이 쉬운 장점이있다.
단점
- 외부단편화가 발생할수있다.
- 파일의 크기는 계속 커질수 있는데(작업을 하기에), 파일의 크기가 꼐속 커지면 연속된 블락을 계속 할당해 저장해야하는데, 그게 어렵다. 즉, 파일이 커져야 하는 경우를 고려해야한다.
Linked Allocation
Linked List를 이용해서 파일을 디스크에 저장하는 방법이다.
블럭들을 노드로 Linked List자료구조에 저장하는 기법이다.
즉,Continuous Allocation과 다르게 비 연속적으로 블럭에 저장한다.
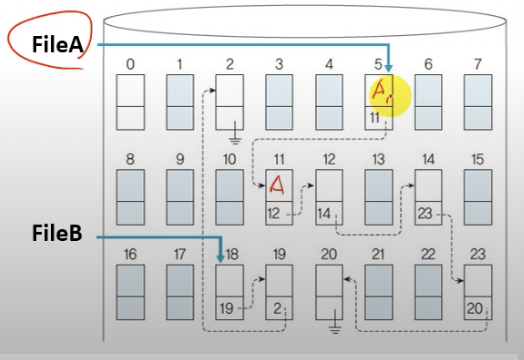
외부단편화도 없고, 디스크 메모리 낭비 문제도 발생하지 않는다.
단점
- Linked List단점인 순차접근이 되게 느리다. 해당파일이 저장된 블럭에 접근하는데 오래걸린다.
- 디스크의 블럭에는 다음 블럭을 가르키는 포인터가 저장되야한다. 즉, 추가적인 공간이 필요하다.
- 사용자가 실수로 다음 노드(블럭)을 가르키는 포인터를 건들면 문제가 발생할수있다. 즉, 신뢰성 문제가 존재한다.
Linked Allocation - FAT
File Allocation Table(FAT)은 Linked Allocation기법을 통해서 파일이 디스크에 저장된다.
좀더 세부적으론, 각블럭의 시작 부분에 다음 블럭의 번호를 기록하기에, 좀더 순차접근의 속도를 높일수있따.
실제로 MS-DOS, Windows 운영체제에서 파일을 디스크에 저장할떄 사용하는 기법이다.
Indexed Allocation
파일이 저장된 블럭의 정보를 따로 모아둔 index table을 이용하는 기법이다.
index table을 보고 파일이 실제로 저장된 블럭에 접근할수 있따.
자바의 ArrayList처럼 인덱스가 있기에 직접접근에 효율적이다.
단점
파일이 저장된 블럭의 정보를 가지고있는 index table이 있다는 것 자체가 단점이다.
메모리에 해당 테이블을 상주하고있어야 한다는 오버헤드가 있다.
Free Space Management
디스크의 빈 공간을 관리하는 기법에 대해서 알아보자.
Bit Vector
가상메모리를 관리하기 위해 존재하는 하드웨어인 Bit Vector과 같이 빈공간과 채워져있는 블럭을 bit(0, 1)을 통해서 구분한다.
간단하다
단점
Bit Vector가 저장되어있는 BITMAP이 따로 존재해야한다. 디스크는 용량이 매애애애우 크다.(1TB ~ 이상일수있음) 그런데, 디스크이 모든 블럭에 대한 정보를 가지고있는 BITMAP도 사이즈가 함께 커지므로 이러한 큰 Map을 메모리에 보관해야하는 단점이있따.(대형 시스템일수록 부적합)
Linked List
빈 블럭들을 Linked List를 통해 연결하는 기법이다.
따로 블럭들의 정보를 가지고있지 않아도 되는 장점이있다.
단점
탐색하는데 너무 비효율적이다. 이유는 위에서말했다.(Linked List자료구조의 단점이다.)
Grouping
빈 블럭들을 그룹으로 묶고, 그룹단위로 Linked List로 연결하는 기법이다.
Linked List처럼 탐색 시간을 확 줄일수있다.
Counting
연속된 빈 블럭의 첫번째 블럭의 주소와, 연속된 빈 블럭의 수를 테이블에 유지하는 기법이다.
따로 이 정보를 저장해야하는 단점이있지만, Continuous allocation같은 시스템에선 매우 효율적인 기법이다.
파일은 디스크에 저장되는 연관된 정보들의 집합이다. OS는 디스크를 블럭단위로 분할하여 관리하는데, 파일이 디스크의 이 블럭들에 어떻게 할당하는지와, 빈 블럭들은 어떻게 관리하여 성능을 높일수 있는지에 대해서 알아보았따. 여러 기법을 중심으로 알아보았다. 자신이 만든 시스템이나 어플리케이션은 어떤식으로 동작하는지 알면 적절한 Allocation methods와 free space management기법중 적절한 것을 골라서 사용하면 시스템의 성능을 비약적으로 높일수있따!! 아는것과 모르는 것의 차이.
결론
OS가 파일을 어떻게 관리하는지, 해당 파일을 저장하는 디스크는 실제로 어떻게 생겼고, OS는 어떻게 디스크를 관리하는지, 그리고 파일들을 구조적으로 분류하게 도와주는 디렉토리는 어떠한 구조들이 있는지, 그리고 파일에 접근하는데 막아주는 보호는 어떻게 하는지, 그리고 실제 파일을 디스크에 어떤 방법으로 할당하고(정확힌 디스크의 블럭에) 파일이 저장되어있지 않은 빈 블럭은 어떤식으로 관리하는지 다양하게 알아보았다. 개념과 기법중심으로 알아보았고, 어떤방식으로 배운것을 사용할수 있는지를 중심으로 고민하면 얻을것이 많다 생각한다.
참고
https://www.youtube.com/watch?v=HGT8HbbB_3w&list=PLBrGAFAIyf5rby7QylRc6JxU5lzQ9c4tN&index=42
'computer science' 카테고리의 다른 글
| HTTP 진화 (HTTP/0.9 -> HTTP/1.0 -> HTTP/1.1 -> HTTP/2.0 -> HTTP/3.0 - QUIC) (2) | 2023.05.13 |
|---|---|
| [OS] 운영체제 I/O System & Disk Management (0) | 2021.10.12 |
| [OS] 운영체제 Virtual Memory Management (0) | 2021.09.19 |
| [OS] 운영체제 Virtual Memory (0) | 2021.09.02 |
| [OS] 운영체제 Memory management (0) | 2021.08.29 |