continuous memory allocation은 프로세스가 연속적으로 메모리에 적재되는것을 의미한다. 그와는 다르게 프로세스가 연속적으로 메모리에 적재되지 않을수도 있다. 이를 Non-continuous memory allocation이라한다. 프로세스가 연속적으로 메모리에 할당되지않고 블럭단위로 여러개로 쪼개서 할당될수 있다면 메모리를 더 효율적으로 사용할수 있을것이다. 그리고 사용되지 않는 블럭(프로세스를 블럭단위로 여러개 나눈것)은 swap device(disk)에 저장하니 메인메모리만 사용할때 보다 더 큰 용량을 관리할수 있다.
Non-continuous memory allocation을 통해서 가상메모리라는 개념이 존재한다. 좀더 자세히 알아보자.
Virtual Memory(Storage)
- Non-continuous memory allocation
- 사용자 프로그램(프로세스)를 여러개의 블럭으로 분할
- 프로세스 실행 시 필요한 블럭만 메모리에 적재(당장 필요하지 않는 블럭은 swap device에 적재)
- 가상메모리란 이렇게 실제 메모리가 아닌 보조기억장치를 실제 메모리처럼 사용하여 더 많은 메모리를 사용할수 있다.
가상메모리의 기법은
- paging system
- Segmentation system
- Hybrid pagin/Segmentation system
으로 구분할수 있다.
그전에 Address Mapping에 대해서 알아야한다.
Address Mapping
논리주소와 메모리에 저장될 실제주소를 매핑하는 것을 의미한다.
Continuous memory allocation은 프로세스가 연속적으로 메모리에 할당 되기 때문에 상대주소를 통해서 쉽게 매핑이 가능하다.
ex) 0 ~ 120의 프로세스를 0 ~ 120까지 주소에 할당 --> 실제 메모리는 200부터 시작 --> 200 ~ 320에 할당
Non-continuous memory allocation은 프로세스가 블럭단위로 여러개로 분할되어 있기에 실제 메모리 어떤 주소에 적재될지는 알지 못한다.(연속적이지 않기 때문에)
그렇기에 가상주소(논리주소)를 실제 메모리에 적재할 주소와 매핑하는 작업이 필요하다.
Non-continuous memory allocation의 프로세스의 블럭들은 가상주소로는 연속적인 주소를 가지고있지만 실제 주소로는 그렇지 않을수 있다.
가상 메모리의 virtual address를 어떻게 real address로 매핑하는 지 알아보자.
Non-continuous memory allocation address mapping

프로세스는 블럭단위로 쪼갤수 있지만 가상주소는 연속적이라 사용자는 프로세스가 메모리에 연속적으로 저장되어있다는 가정하에 실행이 가능하다.(그래야 사용자 입장에선 간단하기 때문에, 물론 실제 메모리에 적재될 주소는 불연속적이다.)
각 블럭의 가상주소와 실제 메모리의 실제주소를 매핑하는 작업이 필요하다.(해당 블럭이 적재된 메모리에 접근하기 위해서는)
이를 Block Mapping이라한다.(블럭의 가상주소와 실제로 적재된 메모리의 주소)
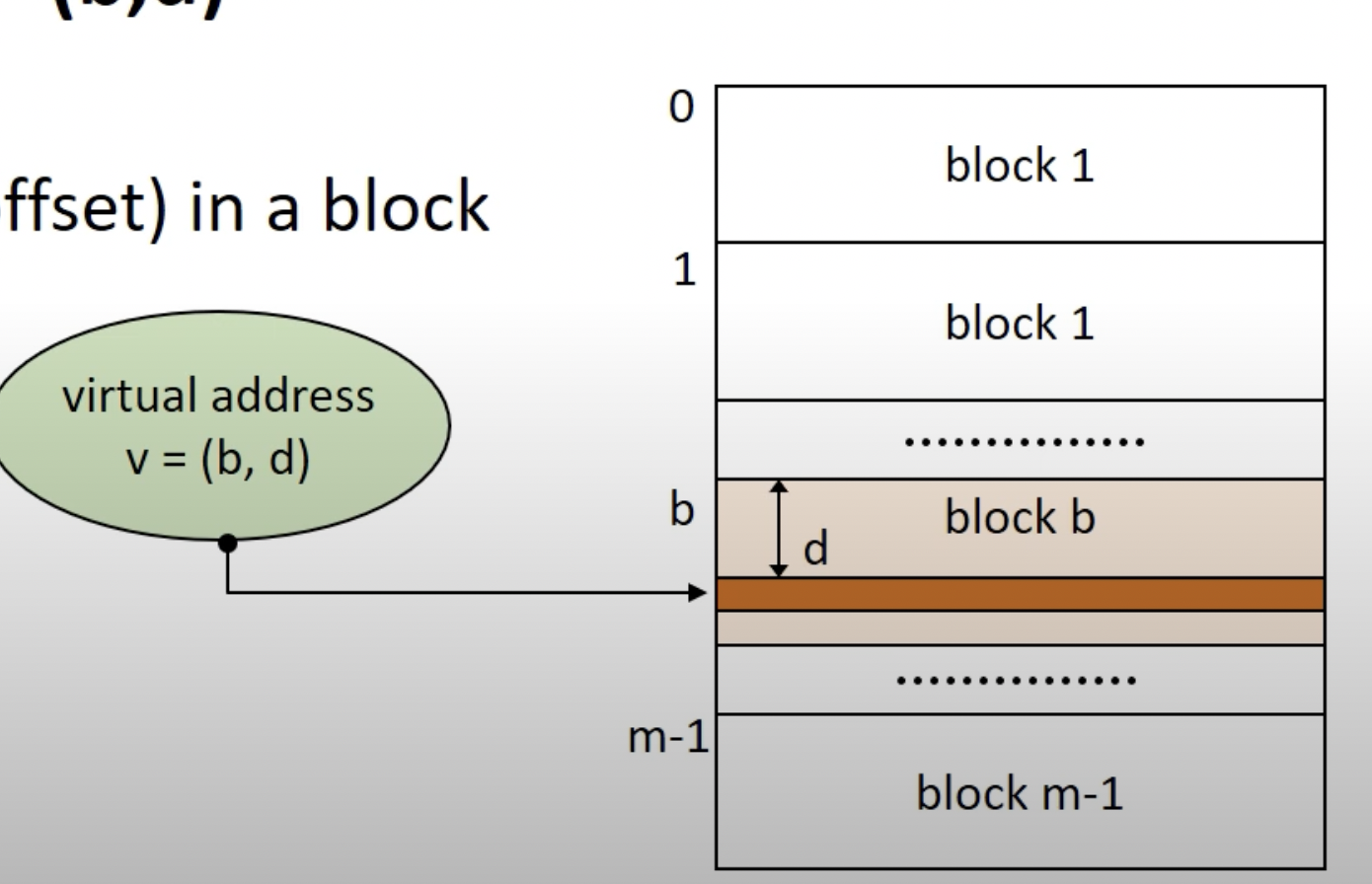
블럭의 Virtual Address : v = (b, d)로 표현할수있다.
b는 블럭의 number이고(블럭의 넘버는 연속적이다.)
d는 블럭안에서 얼마나 거리가있는지를 나타내는 offset(displacement)이다.
Block Mapping을 위해선 가상주소와 실제주소의 정보가 있는 Block Map Table(BMT)가 필요하다.
이 BMT를 통해서 가상주소에 매핑되는 실제주소를 알수 있는 것이다.
블럭매핑의 과정은 이러하다.

BMT를 통해서 해당 블럭넘버 b에 해당되는 실제주소를 알고, residence bit(0, 1중하나로 메모리에 적재되어있는지 적재되어 있지 않은지를 나타내는 flag이다, 적재되 있지않으면 swap device(disk)에 적재되어있어 swap device에서 해당 블럭을 가져와 메모리에 적재하고 residence bit를 1로변경한다.)를 통해서 해당 블럭이 메모리에 적재되어있으면 실제 주소로가서 offset인 d 만큼 더해서 해당 블럭이 저장된 메모리에 접근할수 있는것이다.
Paging System
프로그램을 그냥 분할하는게 아닌 같은 크기의 블록으로 분할하는 기법을 의미한다.(가상 메모리 기법중 하나)
Page란 프로그램의 분할된 블럭을 의미하며 page frame이란 프로그램 블럭이 적재될 메모리의 분할 영역을 의미한다. page와 page frame은 당연하게도 같은 크기이다.
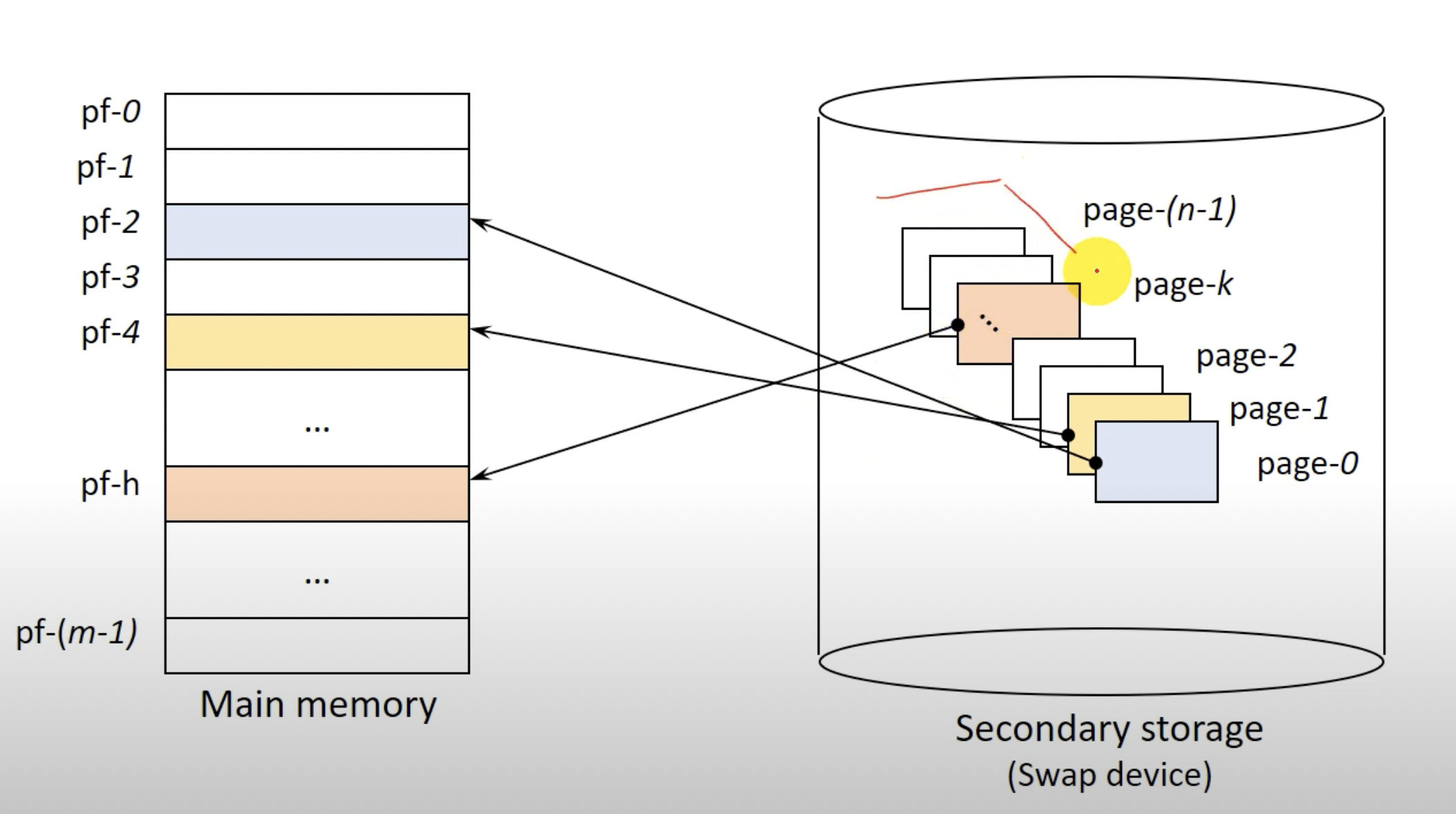
Secondary storage는 디스크와 같은 Swap device를 의미한다. 현재 사용되는 페이지(프로세스의 동일한 크기의 블럭)는 page frame(메모리 분할 영역)에 적재되고 그렇지 않은 page는 스왑디바이스에 존재한다.
Paging System 특징
- 논리적인 분할이아니라 크기에 따른 분할이므로 page 공유 및 보호과정이 복잡하다.(Segmentation보다 더)
- 프로그램을 동일한 크기의 블럭인 page로 분할하였으므로 간다하고 효율적이다.
- 외부단편화는? 절대 생기지않는다. 메모리에 남은 공간의 크기가 더 큰데 페이지가 적재되지 못할 경우는 존재하지 않는다. 왜나면 페이지와 페이지 프레임은 동일한 크기이므로
- 내부단편화는? 생길수 있다. 전체 크기가 310MB 프로그램을 동일한 크기 30MB로 page를 분할하면 10MB남는다. 해당 페이지를 메모리에 적재하면 30MB page frame중 20MB가 남는다. 이는 내부단편화로 메모리를 완벽하게 효율적으로 사용하지 못하는걸 의미한다.
Paging System의 Address Mapping
Virtual address(가상 주소) : v = (p, d)
p는 PMT(Page Map Table)의 번호이다.(위에서부터 오름차순인)
d는 시작주소로부터 얼마나 떨어진지를 나타내는 변수이다.

residence bit가 0이면 page frame에 값이 없는 걸 볼수 있다.(이유는 위에 설명.)
secondary storage는 swap device를 의미하므로 swap device(disk)내에 해당 페이지가 어디에 존재하는지를 나타낸다.
- Paging System Address Mapping mechanism은 세가지가 존재한다.
- Direct mapping(직접 사상)
- Associative mapping(연관 사상)
- Hybrid direct/associate mapping(위 두 방법을 혼합한 방법)
Direct Mapping(직접 사상)
paging system에서의 virtual address(페이지의 가상주소)를 실제 read address(해당 페이지가 적재된 메모리(page frame)의 실제 주소)로 매핑하는 기법중 하나이다.
PMT는 커널(메모리)내부에 존재한다. 그러므로 이점을 유의하면서 살펴보자.
entrySize는 PMT의 entry size로 PMT row의 주소 크기이다.
pageSize는 동일한 크기로 분할한 Page의 크기이다.

v(가상주소) = (p, d)이고 p는 그림과같이 해당 row가 존재하는 PMT의 위치이다.
즉, 실제 메모리에 존재하는 PMT의 row에 접근하기 위해선 b + p *entrySize를 통해서 접근할수있다.
접근하면 페이지 프레임의 위치(p')를 알수있다.(residence bit가 0이면 메모리에 페이지가 적재 안됐다는 것을 의미하므로 해당 페이지를 페이지프레임(메모리)에 적재한뒤 다시 page frame number찾는다.) 페이지프레임의 번호를 찾으면 해당 페이지 프레임이 실제로 존재하는 메모리의 주소를 pageSize와 변수 d를 통해서 알수있다.(pageSize는 동일한 크기로 분할하였으므로 이미 알고있고, 페이지프레임도 동일한 크기이다.)
간단한 것을 볼수있다.
참고로 PMT의 residence bit가 0인 것을 page fault라 하며, 이 page fault는 다시 메모리에 프로세스를 적재해야하므로 running 상태의 프로세스가 asleep(block)상태로 가게된다. 이 때 프로세서(cpu)를 할당받았다 반납해야하므로 context switching이 이루어지게 된다. context switching은 높은 overhead가 존재하므로 page fault는 시스템 성능에 높은 영향을 준다. 그러므로 page fault가 이루어지지 않도록 하는 것이 시스템 성능에 중요한 뽀인트이다.
Direct Mapping 단점
- address mapping(virtual address -> real address)하는 과정에서 메모리의 접근이 두번이루어진다. 이는 성능 저하를 일으킨다.
(1. 메모리에 존재하는 PMT의 row에 접근하는 과정)
(2. 실제 메모리에 적재된 page에 접근하는 과정) - PMT를 위한 메모리의 공간이 별도로 필요하다.
----> 이를 해결하기 위해 address mapping 기법인 associative mapping(연관 사상)이 존재한다.
Associative mapping(연관 사상)
TLB(Translation Look-aside Buffer)라는 것에 PMT를 적재한다.
TLB는 하드웨어로 병렬로 PMT의 row를 찾는것을 도와주고, 메모리가 아니기에 메모리접근을 두번에서 한번으로 줄일수 있다. 즉 성능 향상에 많은 도움을 준다.(그치만 비싸다.)
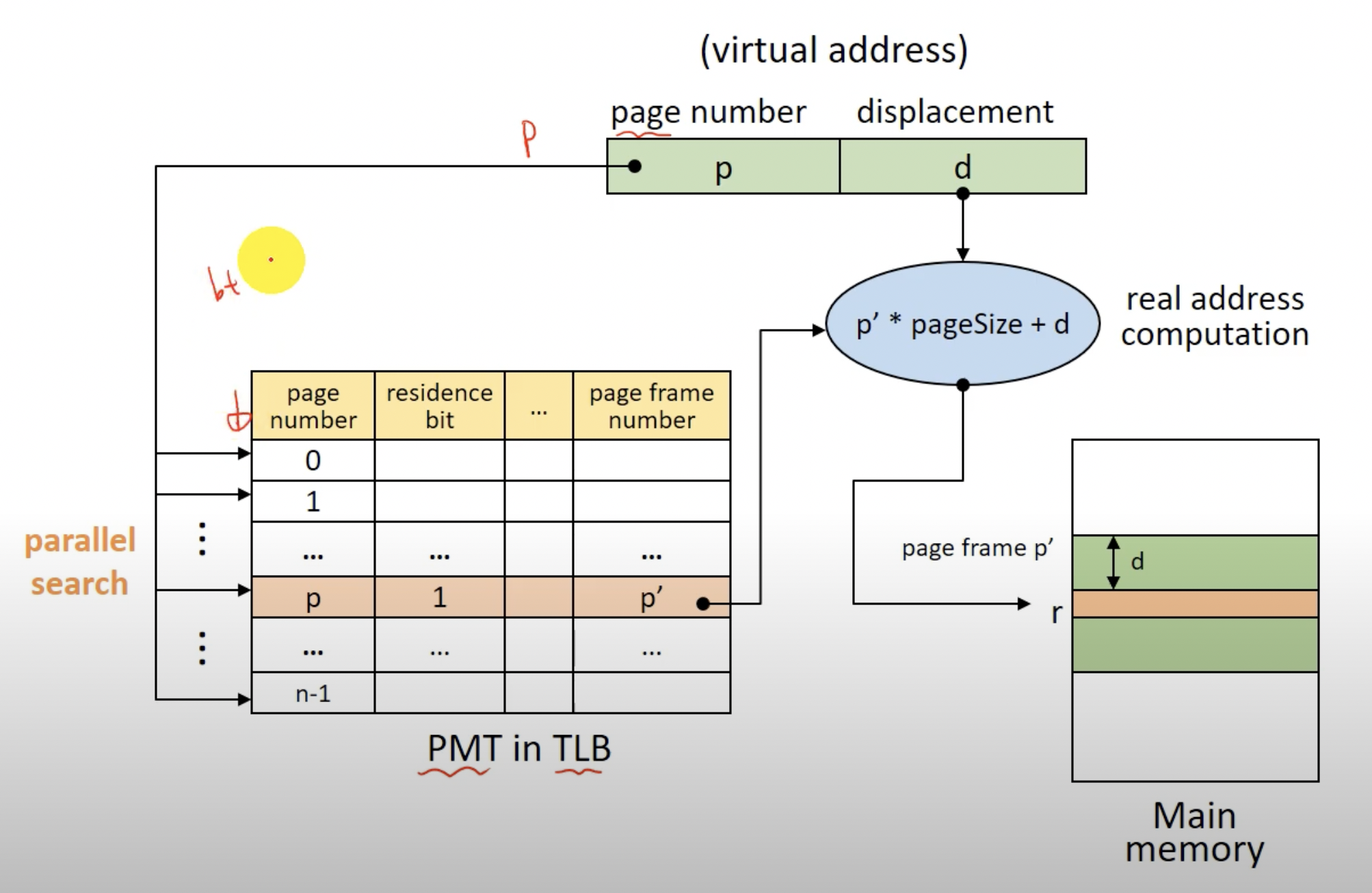
- 낮은 오버헤드와 빠른 속도로 아주 좋은 address mapping 방법이다.
- 그치만 비싸다.. 큰 PMT를 TLB에 넣어서 사용하기가 어렵다.(비싸닌까!, 레지스터도 비싸닌까 조그마한것 사용한다!)
Hybrid Direct/Associative Mapping
Associative mapping(연관 사상)을 이용하면 좋겠지만 TLB가 비싸므로 Direct Mapping과 결합하여 서로간의 장점을 뽑아서 사용하는 Address Mapping기법이다.(가장 현실적이다.)
- 바로바로 메모리에 PMT를 적재하는건 Direct Mapping과 같으나 지역성이라는 특징을 통해 작은 TLB에 PMT의 일부 entry만 적재하는 형태로 address mapping을 하는 기법이다.(지역성은 캐쉬할때 알아보았따!)
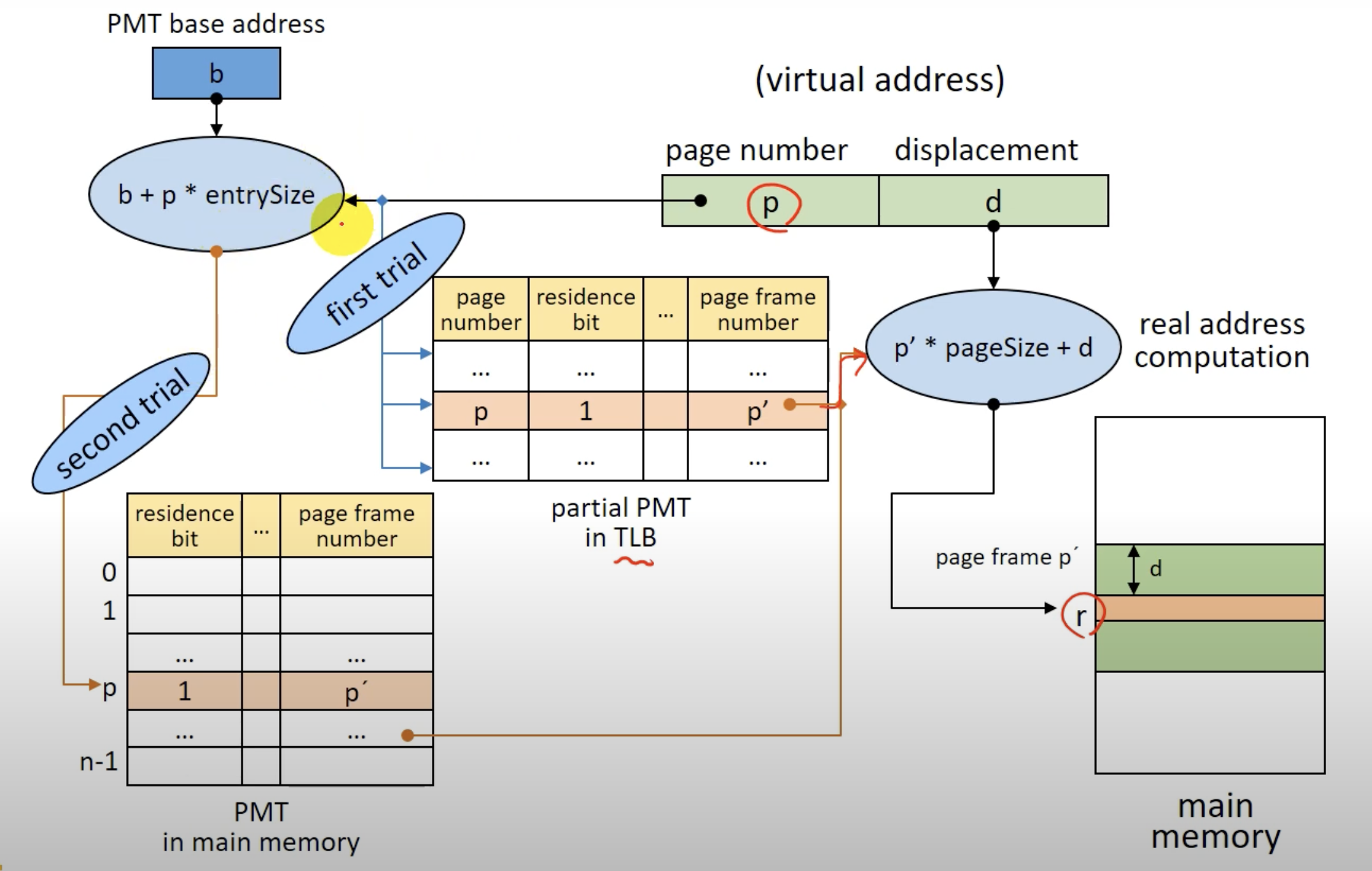
TLB에 찾으려는 PMT의 ROW가 존재하면 바로 연관사상처럼 address mapping하면되고, 없으면 Direct Mapping으로 page frame의 번호를 확인하고 해당 PMT entry를 TLB에 적재하면 된다.(간단하다!)
Hybrid Mapping 기법은 '지역성'이라는 특징(TLB에 적재된 PMT 일부 entry를 또다시 사용할 확률이 높다)을 이용한다.
Paging System의 Memory Management
페이징 시스템에서 메모리 관리를 어떻게 하는지 알아보자.
위에서 알아본거과 같이 페이지와 같은 크기인 페이지 프레임으로 메모리가 분할된다.(FPM과 비슷)
이 페이지 프레임을 관리하기 위한 자료구조가 필요하고 이 자료구조를 Frame table(페이지 테이블)이라 한다.
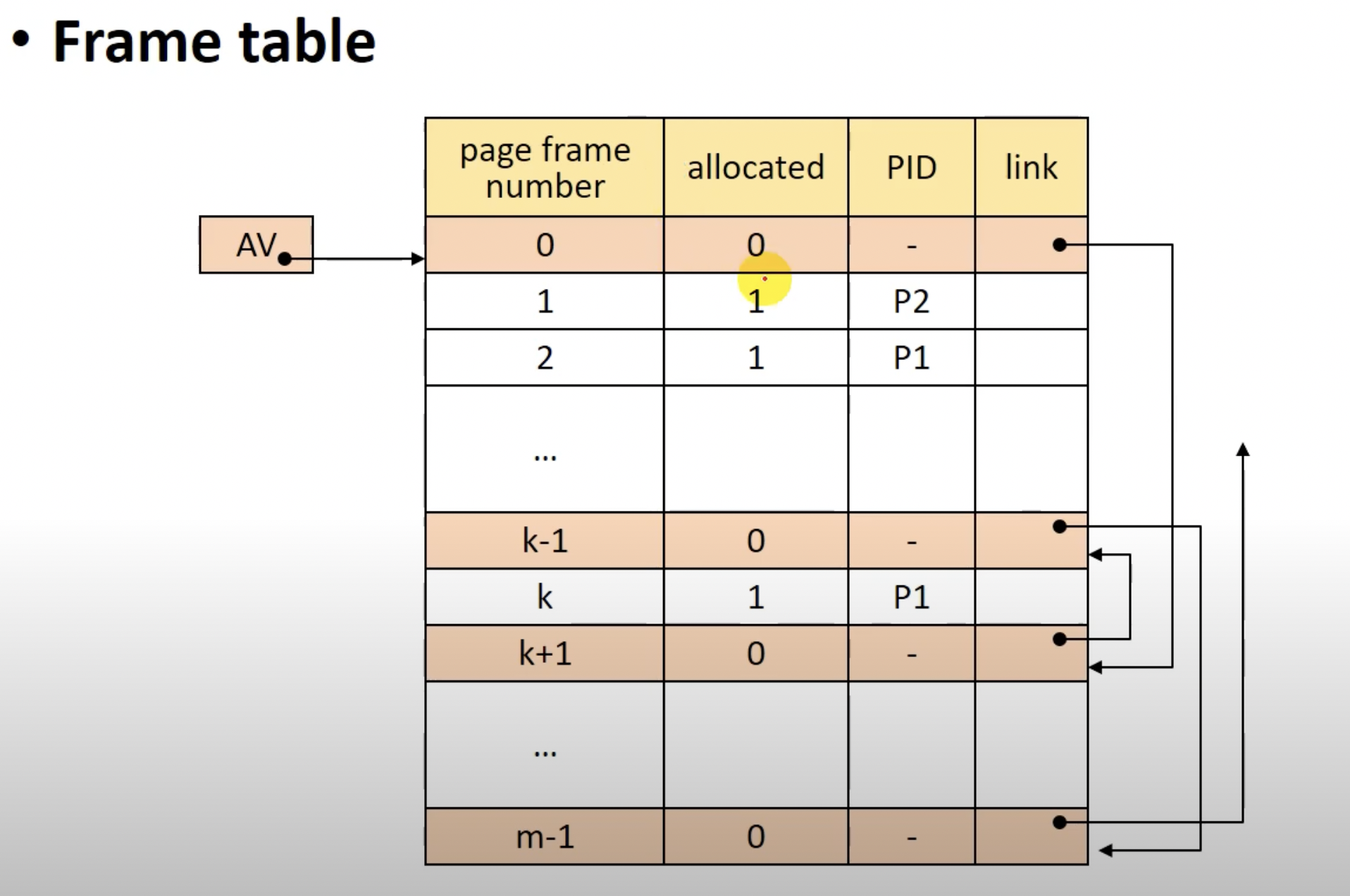
(프레임 테이블)
Paging Sharing(페이지 공유)
여러 프로세스가 같은 페이지를 사용할 경우 메모리에 해당 페이지를 여러개 적재할필요가 없다.
즉, 공유할 페이지를 하나만 메모리에(페이지 프레임에)적재 한뒤 여러 프로세스가 공유하며 사용하면 된다.
공유 가능한 페이지의 종류는
- Procedure page
- Data page
로 분류할수 있다.

하나의 페이지를 여러 프로세스가 공유할 경우의 예시이다. p1, p2, p3의 페이지 테이블을 보면 같은 페이지프레임의 페이지를 사용하는 것을 볼수 있다.
Paging Protection(페이지 보호)
여러프로세스가 페이지를 공유할 때 보안적인 문제가 발생할수 있다.
해당 문제는 Protection bit를 통해서 프로세스가 자원에 대해 접근할수 있는 권한을 비트로 부여하여 해결할수 있다.
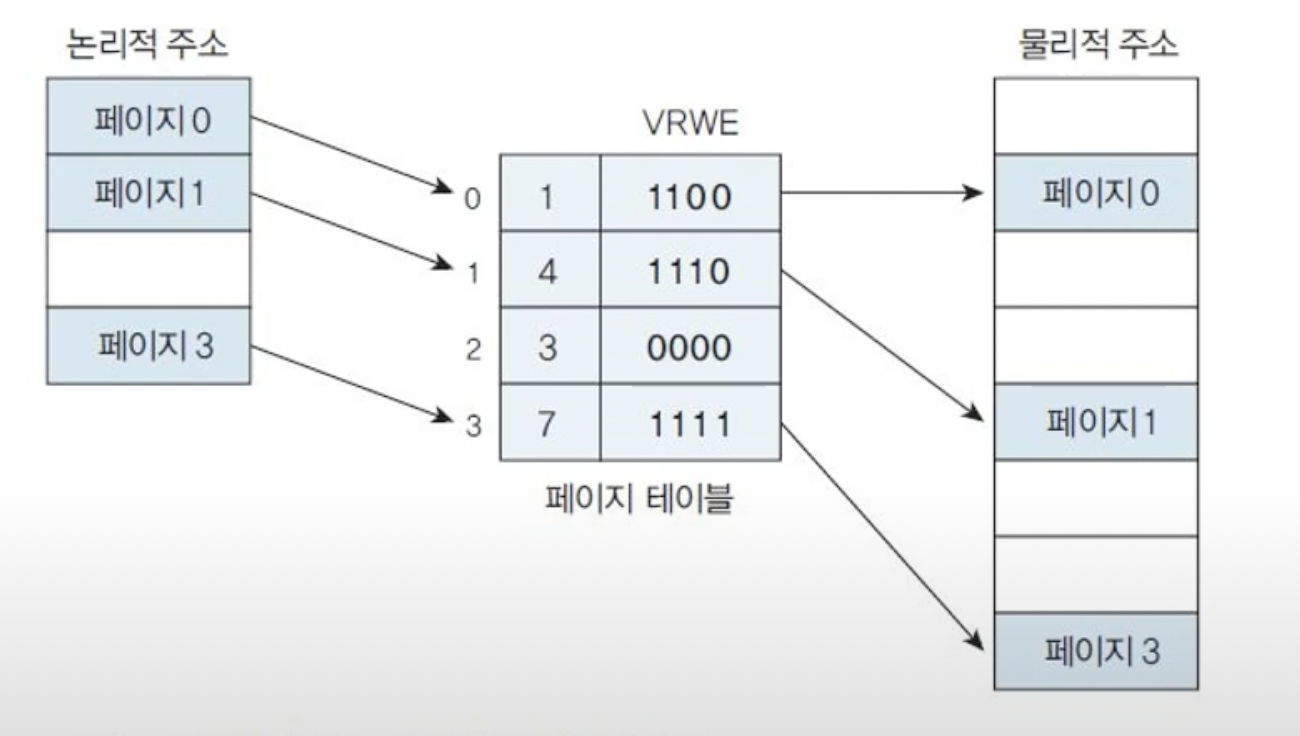
(읽기, 쓰기, 실행등의 권한을 비트로 표현)
페이징 시스템 정리
- 프로그램(프로세스)를 같은 크기의 블럭(페이지)으로 분할
- 메모리도 페이지와 같은 크기의 블럭(페이지 프레임)으로 분할
- 논리적인 이유 없이 단순히 같은 크기로 프로세스를 분할하기 때문에 Paging sharing, Paging Protection등에 대한 문제 해결이 복잡하다.(Segmentation system에 비해)
- 필요한 페이지만 페이지 프레임(메모리)에 적재하여 사용하기에 메모리를 효율적으로 사용할수 있다.
- 메모리에 적재된 페이지 프레임에 접근 하기 위해선 두번의 메모리 접근이 필요하다. 이를 해결하기 위해 TLB와 같은 하드웨어를 사용할수 있다.
Segmentation System
가상메모리 관리하는 기법중 하나로, 페이징 시스템과 다르게 프로세스를 논리적인 크기의 블럭들로 분할하는 기법이다.
즉, 논리적으로 프로세스를 분할하기에, 블럭들은 크기가 모두 다를수 있다. 예를들면 논리적으로 하는일에 따라서 프로세스를, stack, heap, main procedure.. 블럭들로 분할하는 기법이다.
세그먼테이션 시스템의 논리적인 크기로 분할된 블럭을 Segment라고 한다.
특징
- 블럭의 크기를 미리 알수 없으므로 메모리도 미리 분할할수 없다.
- Segment는 논리적인 크기로 분할되었기에 Sharing과 Protection(권한 부여)가 Paging System보다 용이하다.
- 블럭(세그먼트)들의 크기가 모두 다르기에 Address mapping과 메모리 관리의 오버헤드가 Paging System보다 크다.
- 내부단편화는 생기지않는다.(외부단편화는 생길수 있음, 메모리에 적재된 세그먼트가 release되고 나면 외부단편화 생길 가능성 존재함)
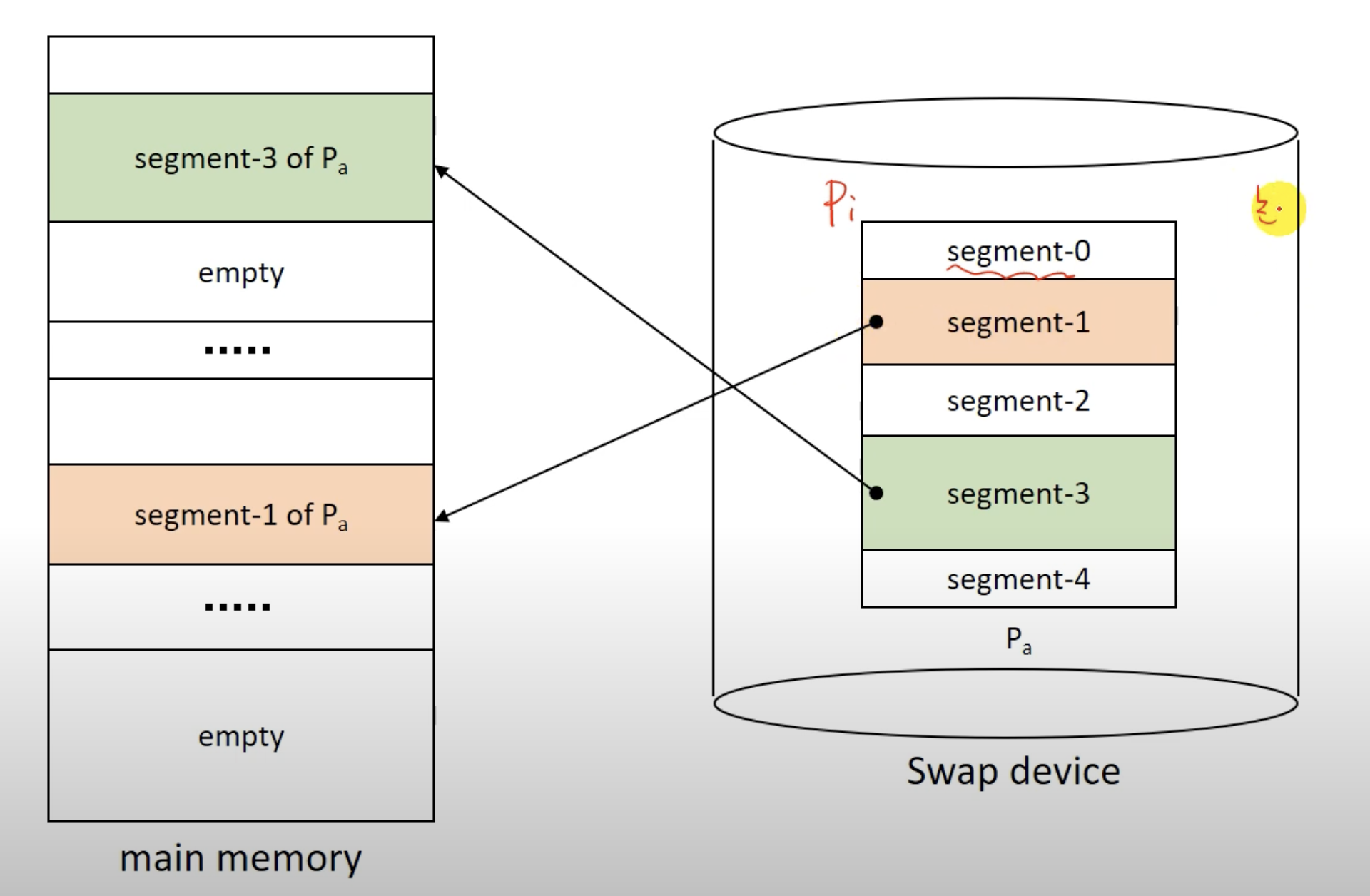
페이징 시스템과 다르게 프로세스가 다 다른 크기의 블럭들로 분할된 것을 볼수 있다.
Segmentation System Address Mapping
virtual address = (s, d)이다.
s는 segment의 번호이고, d는 displacement(offset)이다.
그리고 SMT(Segment Map Table)을 이용한다.
즉, Paging System의 Address Mapping과 유사하다. 단지, 블럭들이 동일한 크기로 분할되어 있지 않으므로 좀더 오버헤드가 큰 차이점이 존재할 뿐이다.
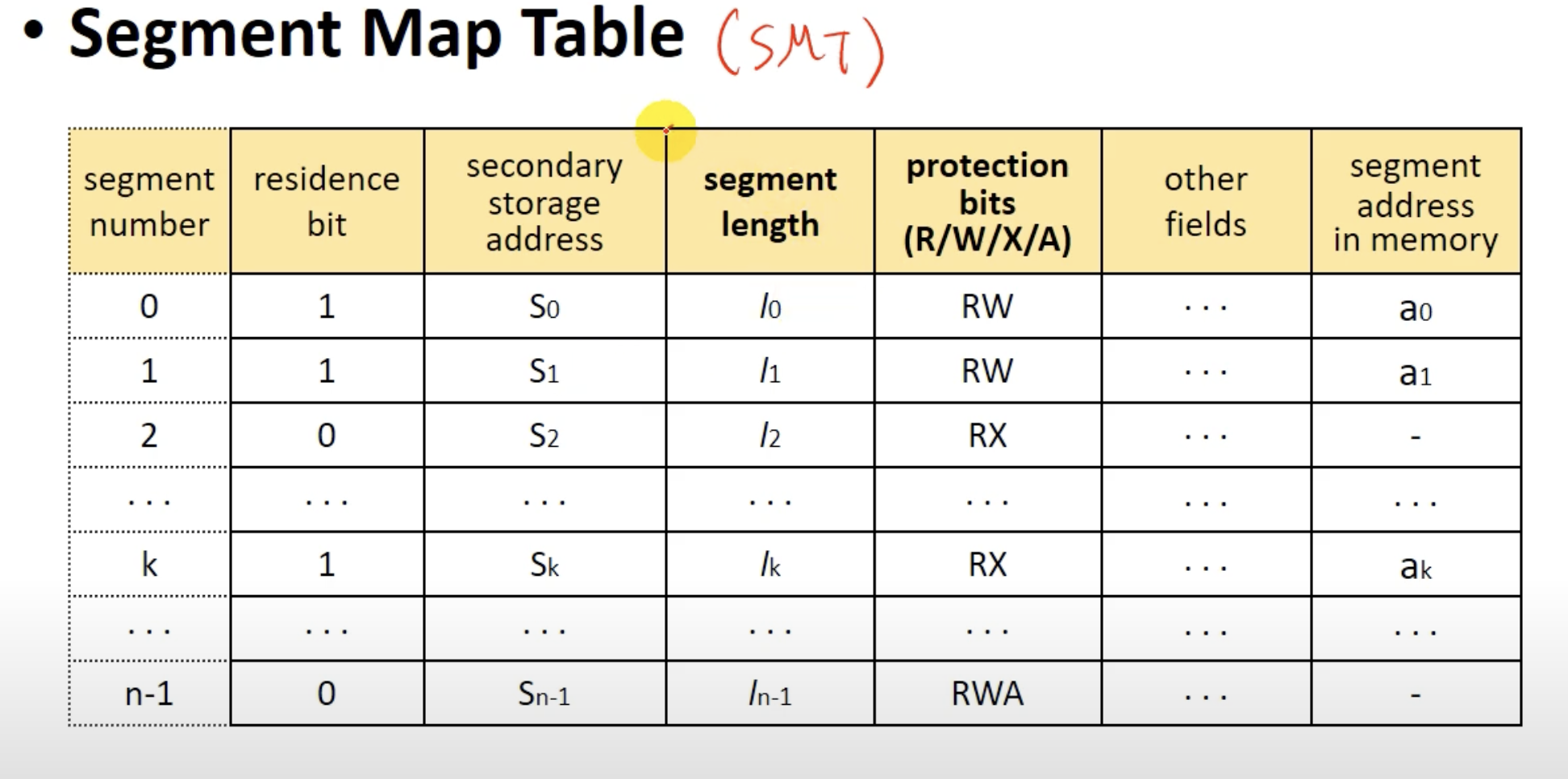
SMT이다. PMT와 거의 동일하지만 세그먼트의 크기를 나타내는 필드인 segment length와 해당 세그먼트의 권한을 나타내는 필드인 protection bits가 있는걸 볼수 있다.
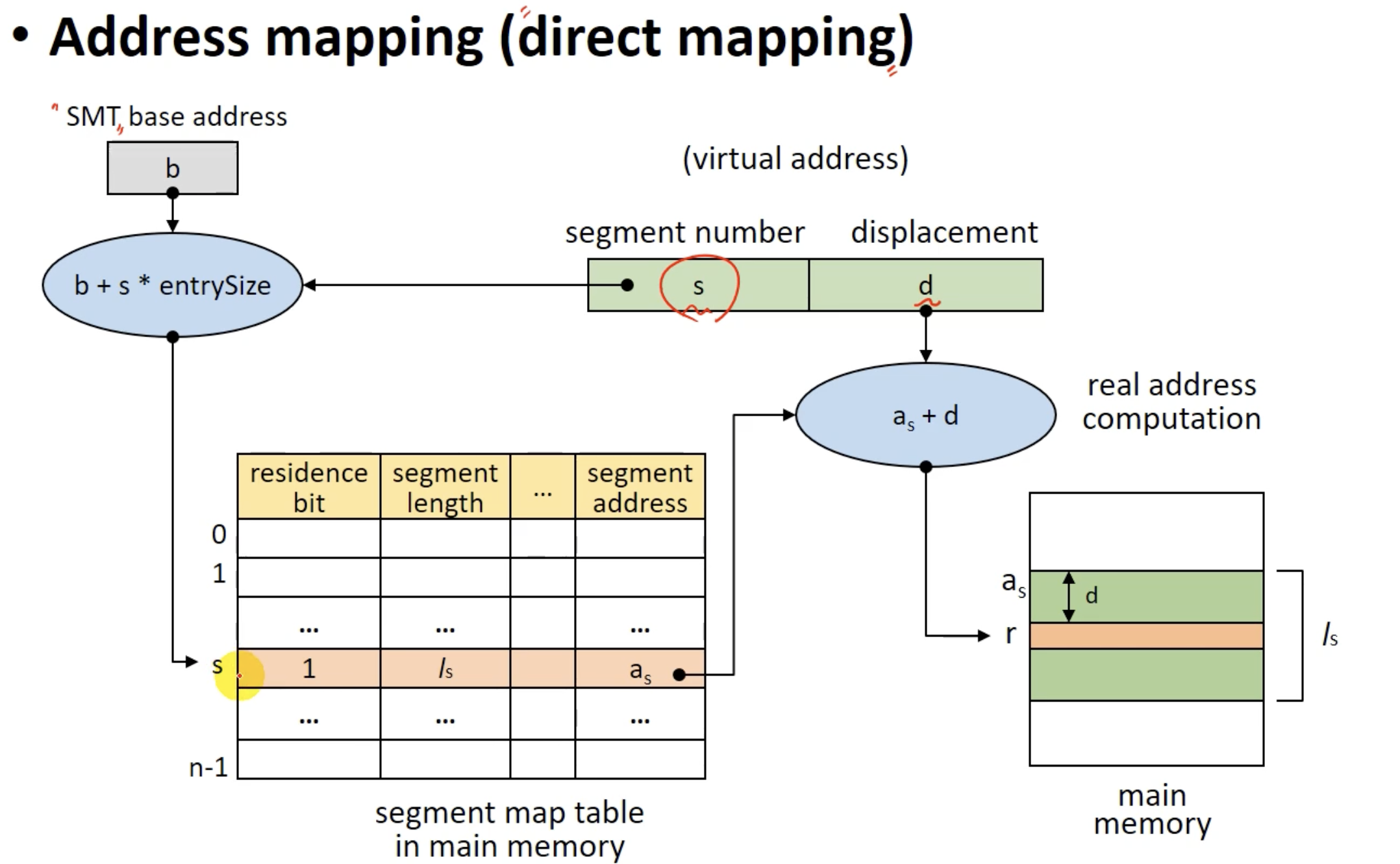
segmentation system의 address mapping과정인데, paging system과 동일하다.
Segmentation system도 SMT를 위한 별도의 메모리공간이 필요한 것과 추가적인 메모리 access때문에 TLB를 통해 address mapping 효율성을 높일수 있다.
하지만 Segmentation system에서는
- d(displacement)가 l(segment length)보다 큰경우 segment overflow exception이 발생할수 있고
- 해당 세그먼트에 허가되지 않은 요청을 하면 segment protection exception이 발생할수 있다.
SMT의 residence bit가 0 이면 paging system과 같이 segment fault로 swap device에서 해당 세그먼트를 메모리에 올려놔야한다. 이는 context switching이 발생하여 오버헤드가 큰 작업이다.
Segmentation System Memory Management
페이징 시스템의 Frame table과 같이 Partition table로 메모리에 적재된 세그먼트를 관리한다.

Segmentation System Segment Sharing / Protection
논리적으로 블럭들이 분할되어 있기에 세그먼트의 공유가 쉽고, 세그먼트마다 protection bit가 존재하여 보호도 쉽다.(페이징 시스템에 비해)
Segmentation System 정리
- 프로세스를 논리적인 크기로 분할
- 그렇기에 세그먼트 보호나 공유가 용이하다.
- 내부단편화 생기지 않는다.
- 블럭들의 크기가 모두 다르므로 페이징 시스템에 비해서 address mapping이나 memory 관리의 오버헤드가 크다.
Paging System vs Segmentation System
| Paging System | Segmentation System |
|---|---|
| 페이지의 크기가 모두 동일하므로 address mapping과 메모리 관리 오버헤드가 적다. | 세그먼트의 크기가 모두 동일하지 않을 수 있기에 address mapping과 메모리 관리 오버헤드가 크다. |
| 논리적인 의미없이 단순히 같은 크기로 프로세스의 블럭들을 분할 | 논리적인 크기로 프로세스의 블럭들을 분할 |
| 페이지의 공유나 보호가 복잡 | 페이지의 공유나 보호가 단순 |
Hybrid paging/segmentation system
가상 메모리 기법 페이징시스템과, 세그멘테이션 시스템에는 장/단점이 있는걸 확인했다. 둘간의 장점을 모두 활용할순 없을까? 그래서 나온것이 Hybrid system이다. 이는 페이징시스템의 장점인 '프로그램을 같은 크기의 페이지로 분할하여 메모리 관리를 쉽게할수 있다'와 세그멘테이션 시스템의 장점인 '프로그램을 논리단위인 세그먼트로 분할하여 블락의 공유와 보호를 쉽게할수 있다'를 둘다 가지게 할수 있다.
어떻게 할까?
- 프로그램을 논리단위인 segment로 분할
- 그 segment를 고정된 크기의 동일한 page들로 다시 분할
- page단위로 메모리에 적재
함으로써 둘간의 장점을 취할수 있다.
즉, 세그먼트를 다시 모두 동일한 크기인 페이지로 나누고 실제 메모리에는 페이지들을 적재한다는 의미이다.
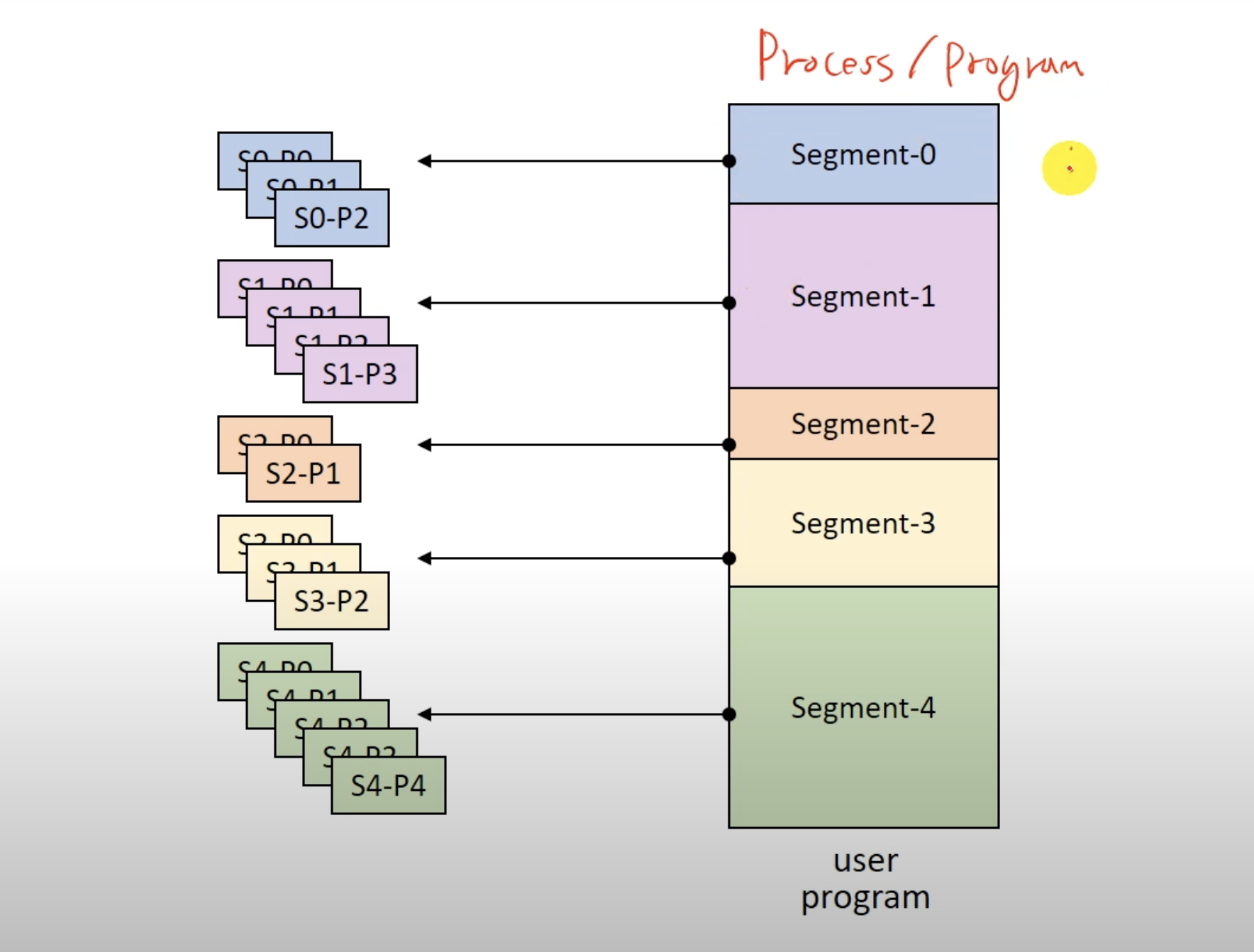
그림으로 확인하면 이와 같다.
Hybrid기법의 Adress mapping
- v = (s, p, d)로, 가상주소는 변수 세개 s, p, d로 표현할수있다.
- s: segment number
- p : page number
- d : offset in a page
- SMT, PMT를 모두 사용한다.
- 각 프로세스 마다 SMT를 사용
- 각 세그먼트마다 PMT를 사용
- Address mapping은 직접 사상, TLB와 같은 HW를 이용한 연관사상 모두 가능
- 메모리 관리는 페이지 프레임들로 구성되므로 FPM과 유사하다.
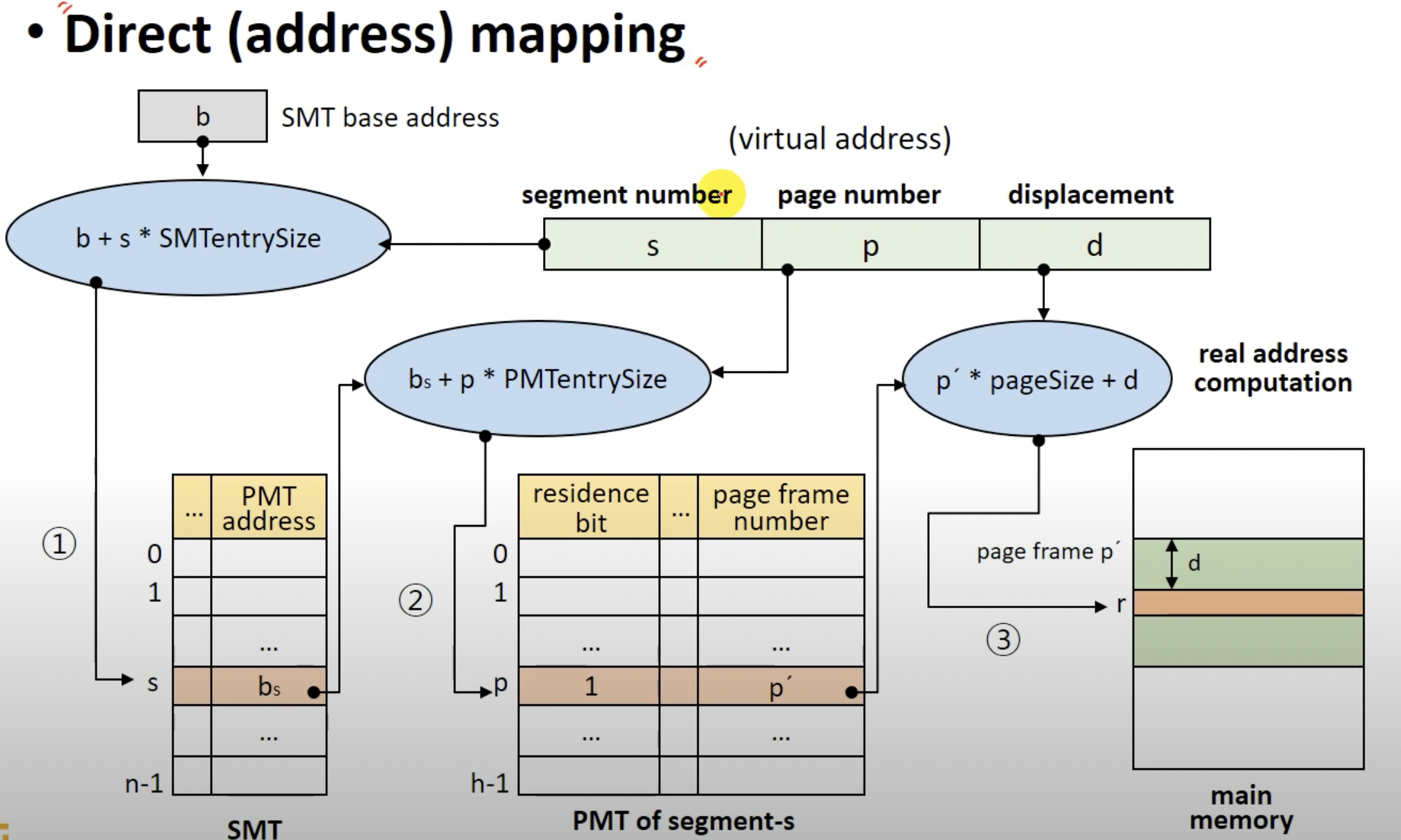
그림으로 표현하면 이와 같다.
- v = (s, p, d)를 실제 주소로 어떻게 매핑하여 실제 메모리에 접근하는지 순차적으로 알아보자.
- SMT의 기본주소 b에 segment number인 s를 SMT의 entry size를 곱한 값을 더하여 SMT의 엔트리에 접근한다. - 실제 메모리에 적재된 SMT중 원하는 엔트리에 접근하게되었다.
- 해당 엔트리에 적힌 PMT의 주소 bs를 통하여 실제 PMT의 엔트리에 접근한다. (bs + page number * PMT의 엔트리 사이즈)
- 접근한 PMT엔트리의 page frame number인 p`를 알게되었다.
- page frame의 번호를 통하여 p` * page size + d를 통해 실제 블럭이 적재된 메모리에 접근하게 된다.
hybrid기법의 SMT에는 해당 세그먼트가 메모리에 적재되어있는지 알수있는 residence bit가 없다. 실제 메모리에 적재 되는 것은 페이지이므로 PMT에 residence bit가 존재한다.
- 이건 직접사상이고 물론, HW인 TLB를 이용하는 연관사상을 통해 훨씬 빠르게 원하는 엔트리에 접근할수 있다.
Hybrid 정리
- 프로그램을 논리적인 세그먼트로 나누고 또 세그먼트를 고정된 같은 크기들인 페이지로 분할한다.
- 이 페이지를 메모리에 적재한다.
- 즉, 동일한 크기의 페이지를 메모리에 적재하기에 메모리 관리 오버헤드가 적고, 논리적인 크기로 미리 분할하였기에 페이지 보호나 공유가 용이하다.
- 동일한 크기들의 페이지가 메모리에 적재되기에 외부단편화는 없다.
- 세그먼트를 페이지들로 분할할때, 마지막 조금 남은 부분도 하나의 페이지로써 메모리에 적재되기에 이때 내부 단편화가 발생하긴 한다.
- 그러나, address mapping과정을 보면 알겠지만 SMT마다 여러개의 PMT를 가지고있으므로 그만큼 메모리 소모가 크다.
- 그리고 메모리에 대한접근도 SMT접근, PMT접근, 페이지가 적재된 메모리에 접근으로 총 세번 이루어 지기 때문에 성능이 저하될수있다.
- 그러나 그만큼 Hybrid기법이 얻는 장점도 많기 때문에 충분히 사용될 필요가 있다.
결론
지금까지 가상메모리에 대해서 알아보았다. 메인메모리 크기보다 프로그램이 돌아가는데 필요한 메모리의 크기가 더 크면 프로그램이 어떻게 돌아가나? 싶었는데 바로바로 가상메모리를 이용해서 지금 당장 필요한 블럭만 메모리에 적재하고 나머지 블럭들은 가상메모리(보조기억장지 = swap device)에 적재함으로써 돌아가는 것을 알게 되었다. 이번엔 실제로 자주 접하는 내용을 공부하게 되어서 도움이 많이되었다.!! 실제로 jdk를 통해 스프링 부트를 실행하는 도중 메인메모리의 부족으로 프로그램을 실행하지 못했는데 swap device를 생성하여 실행을 가능케 하였다.
참고
https://www.youtube.com/watch?v=ctfTntZ-RBo&list=PLBrGAFAIyf5rby7QylRc6JxU5lzQ9c4tN&index=31
https://www.youtube.com/watch?v=Dprd7V842WY&list=PLBrGAFAIyf5rby7QylRc6JxU5lzQ9c4tN&index=30
https://www.youtube.com/watch?v=B_QLTChsi04&list=PLBrGAFAIyf5rby7QylRc6JxU5lzQ9c4tN&index=29
http://youtube.com/watch?v=mTFYeZwPj0s&list=PLBrGAFAIyf5rby7QylRc6JxU5lzQ9c4tN&index=28
https://www.youtube.com/watch?v=YCfP9I4K-8Y&list=PLBrGAFAIyf5rby7QylRc6JxU5lzQ9c4tN&index=28
'computer science' 카테고리의 다른 글
| [OS] 운영체제 File system (0) | 2021.10.04 |
|---|---|
| [OS] 운영체제 Virtual Memory Management (0) | 2021.09.19 |
| [OS] 운영체제 Memory management (0) | 2021.08.29 |
| [OS] 운영체제 Deadlock (0) | 2021.08.20 |
| [OS] 운영체제 프로세스 동기화 & 상호배제 (0) | 2021.07.28 |