안녕하세요!
많은 분들이 기다려 주셔서 드디어 돌아왔습니다앍!
제가 실무에서 경험한 좋은 경험을 다른 분들에게도 공유하고 싶어서 오랜만에 블로그에 글을 올립니다!
다들 쿼리를 개선한 경험이 있으신가요?
쿼리 개선의 글을 찾다보면.. 쿼리만으로 해결하려하지 말고 어플리케이션 레벨로 가져와서 쿼리를 개선할 수 있다라는 글을 많이 보셨을 겁니다아.!!
그런데 어떤 경우에 그래야 할지 감이 잘 안 잡히죠?
왜냐면, mysql RDBMS를 이용한다면, 옵티마이저가 여러 실행계획들 중 현재 데이터 상황(테이블 정보, 인덱스 정보, 데이터 분포도 - 히스토그램)에 맞는 최적의 실행계획을 선택해서 실행하기 때문입니다.
그리고 mysql innodb storage 엔진을 사용한다면, B-Tree 구조로 저장된 인덱스를 통해 데이터를 검색하기에 빠릅니다! (트리는 검색에 특화!)
(물론 인덱스를 적절히 사용할 수 있는 상황에서의 이야기입니다!)
그래서 쿼리를 어플리케이션 레벨의 비즈니스 로직으로 가져와 뭘 딱히 개선할 수 있을까요? 감이 잘 안잡히네요 휴우..
그런데 저는 실무에서 한 방 쿼리를 어플리케이션 레벨로 가져옴으로써 성능을 개선한적이 있는데요!!!!
한번 공유해보겠습니다! 도움이 되셨으면 좋겠어요.
문제 상황
하나의 메인 데이터를 가져와야 하는 상황이였습니다.
그런데 그 메인 데이터에 연관된 데이터들이 너무 많아서 조인으로 가져와야했어요!
심지어 메인 데이터와 관계되는 서브 데이터들은 1 : N 관계였고, 서브 데이터는 또 서브 x2 데이터와 1 : N 관계가 있었어요! 또 서브 x2 데이터는 서브 x3 데이터와 1 : N 관계가 있었어요!!!
ERD로 보면 이렇습니다~

저는 처음엔 한방 쿼리로 해결하려고 했었습니다!
select *
from main_tb
# a정보를 위한 조인
join sub1_tb1 s1t1 on main_tb.id = s1t1.main_tb_id
join sub1_tb2 s1t2 on s1t1.id = s1t2.sub1_tb1_id
join sub1_tb3 s1t3 on s1t2.id = s1t3.sub1_tb2_id
# b정보를 위한 조인
join sub2_tb1 s2t1 on main_tb.id = s2t1.main_tb_id
join sub2_tb2 s2t2 on s2t1.id = s2t2.sub2_tb1_id
join sub2_tb3 s2t3 on s2t2.id = s2t3.sub2_tb2_id
# c정보를 위한 조인
join sub3_tb1 s3t1 on main_tb.id = s3t1.main_tb_id
join sub3_tb2 s3t2 on s3t1.id = s3t2.sub3_tb1_id
join sub3_tb3 s3t3 on s3t2.id = s3t3.sub3_tb2_id
where main_tb.id = 1;이렇게요!!!
그런데 쿼리를 실행했는데 응답이 안오는 겁니다 ㅠ.ㅠ
끈기를 가지고 기다려 봤습니다 ㅠ.ㅠ
드디어 결과 레코드들이 반환되었는데 !!!!!
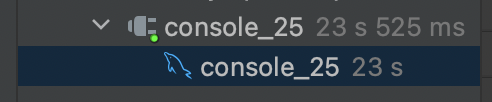
23초나 걸렸습니다 ㅠ.ㅠ 왜 이럴까여
조인 조건도 인덱스를 통해서 조인되었는데 말이죠옹..
그런데 반환된 레코드 수가 1953125개 ~~??

뭔가 문제가 있어보입니다... 저는 메인 데이터 하나를 가져오고 싶었고 그에 대한 연관 데이터를 가져오기 위해 조인했을 뿐인데 DB는 195만개의 레코드를 반환했어요
(Datagrip은 기본적으로 limit 500이 걸려있습니다. 재현하시려면 해당 옵션을 해제하고 쿼리를 실행하셔야합니다~)
해결 방법
열어분!!!
조인이 되면 곱 연산으로 반환되는 레코드 수가 늘어나는걸 아시나요?
메인 데이터의 데이터는 한개 가져오는 상황이지만 1 : N 관계의 연관된 테이블이 많다면 최대 1 * N * N * N ...의 레코드 개수가 반환됩니다.
1개의 메인 데이터와 M개의 테이블이 이렇게 연쇄적으로 1:N관계라면 최대 반환되는 레코드 수는 N^M 입니다 !!!!!!
위의 예시에서 메인 테이블인 main_tb 테이블의 레코드 하나에 대해 1 : 5로 존재하는 연관된 테이블 9 개를 모두 조인하니 5^9 인 1953125 개의 레코드가 반환된것입니다!!!
Database 서버로의 쿼리 요청 수를 줄이기 위해 한방쿼리로 처리한 것이 오히려 성능에 독이되었슴다..
이럴 때, 저는 한방의 다중 조인 쿼리를 어플리케이션 레벨에서 쿼리를 분할하여 해결하였습니다아아앍!!!
아래 쿼리를 좀더 분석해서 해결해 보겠습니다.
select *
from main_tb
# a정보를 위한 조인
join sub1_tb1 s1t1 on main_tb.id = s1t1.main_tb_id
join sub1_tb2 s1t2 on s1t1.id = s1t2.sub1_tb1_id
join sub1_tb3 s1t3 on s1t2.id = s1t3.sub1_tb2_id
# b정보를 위한 조인
join sub2_tb1 s2t1 on main_tb.id = s2t1.main_tb_id
join sub2_tb2 s2t2 on s2t1.id = s2t2.sub2_tb1_id
join sub2_tb3 s2t3 on s2t2.id = s2t3.sub2_tb2_id
# c정보를 위한 조인
join sub3_tb1 s3t1 on main_tb.id = s3t1.main_tb_id
join sub3_tb2 s3t2 on s3t1.id = s3t2.sub3_tb1_id
join sub3_tb3 s3t3 on s3t2.id = s3t3.sub3_tb2_id
where main_tb.id = 1;main_tb의 하나의 정보와 연관된 정보 집합인 a, b, c는 서로 종속적이지 않아요!
예를 들면 메인 데이터를 '축구 선수'라고 해보겠습니다.
그렇다면 a 연관 데이터들은 특정 축구 선수의 친구 정보, b 연관 데이터들은 특정 축구 선수의 경기 정보, c 연관 데이터들은 특정 축구 선수의 취미 생활 정보 라고 예를 들 수 있겠네요.!
서로 종속적이지 않은 연관된 집합들끼리 묶어서 쿼리를 분할하여 요청하면 동일한 데이터 정보를 가져오기 위한 Database Server로의 쿼리 요청 수는 늘어나겠지만 처리해서 반환되는 레코드 수는 확 줄겠죠!?
보통 웹 서버는 커넥션 풀의 커넥션이 존재하여 매번 커넥션을 새롭게 맺고 끊을 필요가 없기에 큰 cost가 아닐수도 있겠네요! 그치만 커넥션은 소중한 자원임을 잊지 맙시다.
위 한방 쿼리를 아래처럼 분할할 수 있을 겁니다!
select *
from main_tb
# a정보를 위한 조인
join sub1_tb1 s1t1 on main_tb.id = s1t1.main_tb_id
join sub1_tb2 s1t2 on s1t1.id = s1t2.sub1_tb1_id
join sub1_tb3 s1t3 on s1t2.id = s1t3.sub1_tb2_id
select *
from main_tb
# b정보를 위한 조인
join sub2_tb1 s2t1 on main_tb.id = s2t1.main_tb_id
join sub2_tb2 s2t2 on s2t1.id = s2t2.sub2_tb1_id
join sub2_tb3 s2t3 on s2t2.id = s2t3.sub2_tb2_id
select *
from main_tb
# c정보를 위한 조인
join sub3_tb1 s3t1 on main_tb.id = s3t1.main_tb_id
join sub3_tb2 s3t2 on s3t1.id = s3t2.sub3_tb1_id
join sub3_tb3 s3t3 on s3t2.id = s3t3.sub3_tb2_id세 쿼리를 동기적으로 연속하여 실행해보도록 하겠습니다.!

각 쿼리는 100ms 정도 걸려서 총 310ms가 걸렸네요!!
23초에 비해선 확연히 실행시간이 준것을 확인할수 있습니다!!
동일한 데이터를 가져오는데 한번의 쿼리요청을 세번의 쿼리요청으로 분할한 것입니다!
멀티 커넥션 환경이라면 세 쿼리를 병렬적으로 요청할수 있을 겁니다! node.js 환경이라면 Promise.all을 이용하면 되겠네요! 그렇다면 세 쿼리의 요청은 300ms가 아닌, 100ms 정도 걸리겠네요.!!
저는 이런식으로 쿼리를 어플리케이션 비즈니스 로직으로 가져와서 쿼리 성능을 개선하였습니다.
관련 코드
직접 테스트 해보실수 있게 세팅해두었슴다!
- https://github.com/YeomJaeSeon/multi-join 해당 레포를 로컬로 clone받습니다!
yarn을 실행해서 관련 라이브러리 모듈 설치하고!- 로컬에 mysql 서버를 띄웁니다.!
host: "localhost", port: "3399", user: "root", password: "root", database: "blog", - ddl.sql 을 그대로 실행해서 create table 합니다!
yarn start를 하여 test 데이터들을 insert 합니다!
그런다음 쿼리를 요청해보며 테스트 해보시면됩니다!
이상입니다! 읽어주셔서 감사합니다
'개발' 카테고리의 다른 글
| nodejs 서버는 언제 사용할까? (16) | 2023.09.23 |
|---|---|
| Dependency Injection (0) | 2023.03.21 |
| 맵드 타입(Mapped Type) (0) | 2022.06.13 |
| eslint, prettier 그리고 github action (0) | 2021.11.14 |
| ec2에 mysql server를 이용해서 spring boot서버를 배포해보자. (1) | 2021.09.16 |